Podíváme-li se na nějaký přehled knihoven pro práci s XML (např. http://www.xmlsoftware.com), zjistíme, že pro Javu existuje zaručeně největší množství knihoven. Tento stav má několik příčin – jednak je Java poměrně oblíbený jazyk, který je díky svému návrhu nezávislý na platformě. Donedávna byla také Java jedním z mála jazyků, který umožňoval snadnou práci s textovými řetězci v Unicode tak, jak to XML vyžaduje.
Rozhodnete-li se ve vaší aplikaci použít parser s rozhraním DOM nebo SAX, máte na výběr hned z několika nejrůznějších implementací. Mezi nejznámější javový parser dnes bezesporu patří Xerces, který původně vyvinula IBM, ale dnes se o jeho další vývoj stará Apache Software Foundation. Podobných parserů však naleznete mnohem více – např. Crimson nebo Ælfréd. Jediný problém je v tom, že napsané aplikace jsou závislé na konkrétním parseru, i když používáme nějaké standardní rozhraní. Liší se totiž kód potřebný pro vytvoření instance parseru.
Podobná situace vládne i na poli XSLT procesorů. Existuje jich několik (Xalan, Saxon) a každý původně přišel se svým vlastním rozhraním.
Roztříštěnost rozhraní si architekti Javy naštěstí uvědomili, a tak postupně vzniklo několik rodin rozhraní JAX. JAX v tomto případě znamená Java API for XML …. V současné době těchto API existuje pět:
JAXP (Java API for XML Processing) – rozhraní pro zpracování XML dokumentů – podporuje DOM, SAX a XSLT transformace.
JAXB (Java Architecture for XML Binding) – umožňuje ze schématu vygenerovat třídy, na které se mapuje XML dokument.
JAXM (Java API for XML Messaging) – obecné rozhraní pro posílání XML zpráv. V současné době obsahuje implementaci protokolu SOAP.
JAXR (Java API for XML Registers) – rozhraní pro přístup k různým XML registrům – například k UDDI registry s popisy webových služeb.
JAX-RPC (Java API for XML-based RPC) – rozhraní pro implementaci vlastních klientů i serverů webových služeb nad standardy SOAP a WSDL. Toto rozhraní je na vyšší úrovni než JAXM, které se ze stručného popisu může zdát velmi podobné. JAXM je messagingové rozhraní pro posílání jakýchkoliv zpráv včetně asynchroních. Oproti tomi JAX-RPC poskytuje jen rozhraní pro vzdálené volání funkcí s modelem požadavek/odpověď.
Pouze první rozhraní JAXP je plně standardizováno, ostatní jsou v různých fázích standardizačního procesu JSR. Poslední verzi všech XML rozhraní si můžete stáhnout pod názvem Java XML Pack.
JAXP z velké části přebírá rozhraní DOM a SAX pro práci s XML dokumenty a rozhraní TrAX pro volání XSLT transformací. Navíc však přidává tovární metody, které umožňují vytvoření SAX nebo DOM parseru a XSLT procesoru. Lze tak psát aplikace, nezávislé na konkrétní implementaci parseru a použitý parser lze dokonce měnit při spouštění nastavením odpovídající systémové vlastnosti.
Pokud potřebujeme v aplikaci použít SAX parser, musíme si nejprve vytvořit tovární objekt:
SAXParserFactory spf = SAXParserFactory.newInstance();
Na něm můžeme nastavit vlastnosti nově vytvářených parserů – například můžeme požádat o vytvoření validujícího parseru:
spf.setValidating(true);
Nyní si už můžeme vytvořit nový parser:
SAXParser parser = spf.newSAXParser();
Nyní musíme definovat obsluhu událostí, které nás zajímají. Nejjednodušší je vytvořit si potomka třídy DefaultHandler, která definuje prázdnou obsluhu pro všechny události. Konkrétní ukázku sečtení faktury zapsané v XML naleznete na CD-ROMu, v textu by byla příliš dlouhá. Nakonec stačí vytvořit instanci naší třídy pro obsluhu událostí a předat parseru dokument ke zpracování.
MyHandler handler = new MyHandler();
parser.parse("faktura.xml", handler);Stejný úkol – sečtení faktury – můžeme samozřejmě naimplementovat i pomocí rozhraní DOM. Nejprve si opět vytvoříme tovární objekt:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
Nyní si připravíme objekt, který je schopný vytvořit nový DOM dokument:
DocumentBuilder builder = dbf.newDocumentBuilder();
DOM dokument můžeme vytvářet přímo v paměti nebo se do něj můžeme načíst již existující XML dokument:
Document doc = builder.parse("faktura.xml");Od této chvíle můžeme s celým dokumentem dle libosti manipulovat. Jediná nepříjemnost je v tom, že rozhraní DOM je hodně abstraktní a obecné – jinak by jej nešlo implementovat v širokém spektru jazyků. Praktický důsledek pak pocítí vývojář v tom, že i pro zdánlivě jednoduché operace je zapotřebí napsat poměrně dlouhý kód.
// získání všech elemementů cena
NodeList nl = doc.getElementsByTagName("cena");
// průchod uzly
int n = nl.getLength();
double suma = 0;
double sumaDPH = 0;
for (int i=0; i<n; i++)
{
Element node = (Element)nl.item(i);
double sazbaDPH = Double.parseDouble(node.getAttribute("dph")) / 100;
// obsah elementu může být ve více uzlech (rozdělený např. komentáři)
StringBuffer cena = new StringBuffer();
NodeList inl = node.getChildNodes();
int m = inl.getLength();
for (int j=0; j<m; j++)
{
// zajímají nás jen textové uzly
if (inl.item(j).getNodeType() == Node.TEXT_NODE)
cena.append(inl.item(j).getNodeValue());
}
double castka = Double.parseDouble(cena.toString());
suma += castka;
sumaDPH += sazbaDPH * castka;
}
// výpis statistiky
System.out.println("Celkem Kč: " + suma);
System.out.println("Celkem DPH: " + sumaDPH);Průchod všech elementů s názvem cena můžeme implementovat velice snadno díky metodě getElementsByTagName, který vybere všechny elementy daného jména. Zjistit hodnotu atributu na vybraných elementech je rovněž snadné – k tomu slouží metoda getAttribute(). Problém je však se získáním obsahu elementu cena. Ten sice většinou obsahuje jen jeden další textový uzel s cenou položky faktury, ale kromě toho může obsahovat např. i komentář nebo instrukci pro zpracování:
<cena><!-- pozlobíme programátora --> 123 <?xxx ukáže se, zda počítá se všemi možnostmi vstupu?> </cena>
Tento kus XML dokumentu by aplikace měla chápat stejně jako:
<cena> 123 </cena>
Při získávání ceny proto aplikace musí projít všechny děti uzlu cena a zpracovat jen ty, které odpovídají textovému uzlu. Právě tuto nepohodlnost se snaží odstranit speciální pro Javu navržená rozhraní jako např. JDOM.
JAXP obsahuje i rozhraní pro volání XSLT transformací, které je nezávislé na použitém XSLT procesoru. Navíc jako vstupy a výstupy transformace lze použít kromě souborů i DOM stromy v paměti nebo proudy SAX událostí. Slouží k tomu speciální třídy StreamSource, DOMSource a SAXSource a jejich obdoby pro zápis výsledku (StreamResult, DOMResult a SAXResult). Můžeme tak řetězit několik transformací za sebou bez nutnosti ztrácet čas serializací výsledku do souboru a následným parsováním. Můžeme také transformovat XML dokumenty vytvořené přímo v paměti.
Jak se tedy z programu volá transformace. Nejdříve si zase musíme vytvořit tovární objekt:
TransformerFactory trf = TransformerFactory.newInstance();
Nyní si už můžeme vytvořit „transformátor“ – objekt s XSLT procesorem. Při vytváření se rovnou může zadat styl, který popisuje transformaci.
Transformer transformer = trf.newTransformer(new StreamSource("faktura.xsl"));Nakonec nezbývá nic jiného než, než provést transformaci XML dokumentu (v našem případě jde o DOM dokument v paměti) a někam ji uložit (v našem případě do souboru):
transformer.transform(new DOMSource(doc),
new StreamResult("faktura.html"));Transformační API JAXPu lze použít na ještě jednu velmi užitečnou věc – pro serializaci XML dokumentů do souborů. Ani DOM ani SAX neobsahuje metody pro zapsání XML dokumentu zpět do souboru (bude to umět až DOM3). Můžeme si proto vytvořit „transformátor“ bez stylu a nastavit parametry serializace jako kódování apod.
serializer = trf.newTransformer();
serializer.setOutputProperty("encoding", "windows-1250");
serializer.transform(new DOMSource(doc),
new StreamResult("dokument.xml"));Obrázek 6. Struktura základních tříd rozhraní JAXP a jejich použití
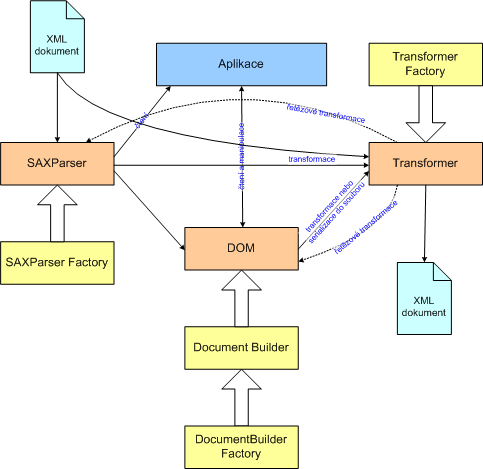 |
JAXP je dnes považováno za standardní API pro práci s XML v Javě. Dokazuje to i jeho zařazení do J2EE 1.3 a do standardní Javy od verze 1.4. Již dnes existují tři verze rozhraní – 1.0, 1.1 (přidala podporu DOM2, SAX2 a XSLT) a 1.2 (podpora validace oproti XML schématům). Java tak má standardní API pro práci s XML – pozdě, ale přece.
Rozhraní JDOM vzniklo jako speciální XML rozhraní pro Javu. Použití DOM a SAXu je v mnoha typických případech těžkopádné, a tak se autoři rozhodli vytvořit API přesně na míru šité Javě. Jejich cílem bylo rozhraní, které 80 % problémů vyřeší s 20 % námahou.
Oproti DOMu je snazší především manipulace s dokumentem, ale i jeho čtení. Výsledný kód bývá až o polovinu kratší – záleží samozřejmě na konkrétní aplikaci. JDOM neobsahuje vlastní parser, o samotné čtení XML dokumentu se musí starat jiný parser. JDOM obsahuje třídy DOMBuilder a SAXBuilder, které umožňují načíst dokument přes SAX parser, případně z existujícího DOM stromu vytvořit JDOM. Podobné je to i s výstupem. Pokud dokument v paměti upravíme, můžeme ho buď zapsat do souboru (XMLOutputter), převést na DOM strom (DOMOutputter) nebo z něj vygenerovat proud SAX událostí (SAXOutputter). Do JDOM lze zabalit i vstupy a výstupy pro XSLT transformaci (JDOMSource a JDOMResult).
V současné době probíhá v rámci Java Community Process (JCP) přijímaní JDOMu jako standardního javového API (JSR-102). Podpora JDOM by se měla objevit i v příští verzi JAXPu.
Abychom si ukázali rozdíl mezi DOM a JDOM, podíváme se na implementaci součtu faktury pomocí rozhraní JDOM. Nejprve musíme vytvořit JDOM strom dokumentu. V našem případě pro samotné čtení dokumentu použijeme SAX parser.
SAXBuilder parser = new SAXBuilder();
Document doc = parser.build("faktura.xml");S dokumentem doc nyní můžeme dle libosti pracovat. Všimněte si, že pro vracení seznamu dětí se nepoužívají žádné speciální třídy, ale klasické javové kontejnery.
List polozky = doc.getRootElement().getChildren("polozka");
Iterator i = polozky.iterator();
while (i.hasNext())
{
Element polozka = (Element)i.next();
double castka = Double.parseDouble(polozka.getChildText("cena"));
double sazbaDPH = Double.parseDouble(polozka.
getChild("cena").getAttributeValue("dph")) / 100;
suma += castka;
sumaDPH += sazbaDPH * castka;
}Největší úsporou práce je metoda getChildText, která vrací textový obsah elementu včetně textového obsahu jeho případných podelementů.
Další alternativa ke standardním rozhraním je DOM4J, které vzniklo odštěpením od JDOM. Jeho použití a rozdíly oproti DOM jsou proto velmi podobné jako u JDOMu, liší se jen filozofie, jakým je API postaveno. DOM4J opět umí načítat XML data z různých zdrojů (včetně DOM a SAX), stejně tak zapisovat a můžeme ho použít i jako vstup či výstup XSLT transformace. Jedinečnou výhodou je integrovaná podpora rozhraní XPath, která ze čtení a zpracování XML dokumentů dělá hračku. Použití XPathu si ukážeme opět na sečtení faktury. Elementy, které se mají sečíst, přitom vybereme XPath výrazem /faktura/polozka/cena.
// získání a zpracování všech položek faktury
List polozky = doc.selectNodes("/faktura/polozka/cena");
Iterator i = polozky.iterator();
while (i.hasNext())
{
Element cena = (Element)i.next();
double castka = Double.parseDouble(cena.getText());
double sazbaDPH = Double.parseDouble(cena.attributeValue("dph")) / 100;
suma += castka;
sumaDPH += sazbaDPH * castka;
}
// výpis statistiky
System.out.println("Celkem Kč: " + suma);
System.out.println("Celkem DPH: " + sumaDPH);Parsery a API, o kterých jsme dosud mluvili, jsou většinou knihovny o velikosti stovek KB. Electric XML je velmi malý parser s vlastním API – knihovna má velikost pouze 46 KB a můžeme ji proto směle použít i v Java appletech. Rozhraní pro přístup k dokumentu je podobné jako u JDOM, navíc Electric XML obsahuje i podporu pro podmnožinu XPathu.