- 3.1. Datové typy
- 3.2. Jednoduché datové typy
- 3.3. Komplexní datové typy
- 3.4. Globální a lokální deklarace
- 3.5. Jmenné prostory
- 3.6. Připojení schématu k dokumentu
- 3.7. Přístupy k návrhu schématu
- 3.8. Práce s prázdnými hodnotami
- 3.9. Zajištění jedinečnosti hodnot
- 3.10. Referenční integrita
- 3.11. Objektově orientované rysy
- 3.12. Modularizace schémat
- 3.13. Omezení schémat
- 3.14. Dokumentování schématu
- 3.15. Novinky v XML Schema 1.1
Pro rychlé vpravení do problematiky si rovnou ukážeme jednoduchý příklad XML schématu a dokumentu XML, který mu vyhovuje. Dejme tomu, že chceme vytvořit schéma popisující dokumenty XML vhodné pro přenos informace o jednom zaměstnanci. U zaměstnance nás přitom bude zajímat jeho identifikační číslo, jméno, příjmení, plat a datum narození. Tyto informace můžeme v XML zachytit následujícím způsobem:
<zamestnanec id="101"> <jmeno>Jan</jmeno> <prijmeni>Novák</prijmeni> <plat>25000</plat> <narozen>1965-12-24</narozen> </zamestnanec>
Odpovídající schéma tedy musí definovat, že dokument musí
obsahovat element zamestnanec, který obsahuje
atribut id a čtyři podelementy
jmeno, prijmeni,
plat a narozen. Obsah těchto
elementů přitom musí odpovídat určitému datovému typu. Všechny tyto
požadavky může zachytit následující jednoduché XML schéma.
w
x
s<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="zamestnanec"> <xs:complexType> <xs:sequence> <xs:element name="jmeno" type="xs:string"/> <xs:element name="prijmeni" type="xs:string"/> <xs:element name="plat" type="xs:decimal"/> <xs:element name="narozen" type="xs:date"/> </xs:sequence> <xs:attribute name="id" type="xs:integer"/> </xs:complexType> </xs:element> </xs:schema>
Vidíme, že celé schéma je dokument XML, který používá speciální
elementy. Všechny tyto elementy musí patřit do jmenného prostoru
http://www.w3.org/2001/XMLSchema. Obvykle se pro
tento jmenný prostor používá prefix xs nebo
xsd.
Celé schéma musí být vždy uzavřeno v elementu schema obsahujícím definice elementů, které lze
použít jako kořenové elementy, tj. dokument XML jimi začíná. Definice
elementu se zapisuje pomocí elementu
element.
Pro každý element musí schéma určit jeho typ. Rozlišovány jsou
přitom dva druhy typů – jednoduché a komplexní. Jednoduché typy
se používají pro skalární hodnoty jako řetězec, číslo, datum apod.
Obsahuje-li element však další elementy nebo atributy, musíme použít
komplexní typ (complexType). Pomocí elementu
sequence říkáme, že zaměstnanec se skládá z po
sobě následujících elementů pro jméno, příjmení, plat a datum
narození. Každý z těchto elementů je povinný, má určené své jméno
pomocí atributu name a datový typ
pomocí atributu type. Datové typy
se uvádějí jako kvalifikované názvy patřící rovněž do jmenného
prostoru XML schémat.
Atributy se deklarují až za vnořenými elementy pomocí elementu
attribute. U atributu rovněž musíme určit jeho
název a datový typ.
Datové typy jsou samotným základem XML schémat, protože v nich je v podstatě vše datový typ. Jak jsme již řekli, datové typy mohou být jednoduché či komplexní.
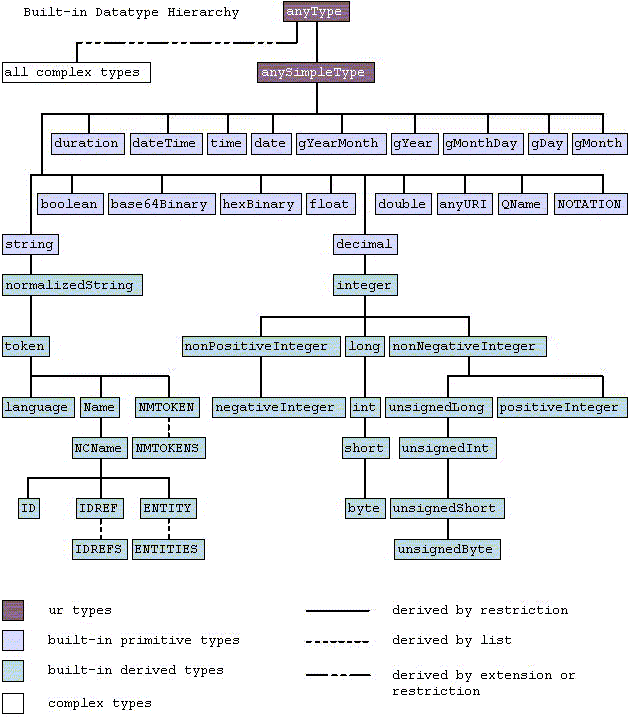
Největší síla XML schémat spočívá v možnosti definovat si vlastní datové typy. Ty přitom mohou vznikat zejména restrikcí nebo rozšířením některého z již existujících typů. Jako základ pro odvozování našich uživatelských typů můžeme použít některý ze zabudovaných typů. Na obrázku 3.1 – „Hierarchie zabudovaných datových typů“ si můžete prohlédnout hierarchii zabudovaných datových typů. Obrázek byl převzat přímo ze specifikace [8].
XML schémata obsahují běžné základní datové typy jako textový
řetězec, celá a desetinná čísla, binární data, logická hodnota, datum,
čas, časový interval a několik typů převzatých z DTD pro jejich
snazší konverzi do XML schémat. V mnoha případech si
s těmito typy vystačíme. Naše první ukázka si například naprosto
vystačila se zabudovanými typy pro textové řetězce
(string), datum (date) a
desetinné číslo (decimal).
Tabulka 3.1. Zabudované datové typy
| Typ | Popis | Ukázka/Poznámka |
|---|---|---|
| string | řetězec znaků | ahoj |
| boolean | logická hodnota | true, false,
1, 0 |
| decimal | desetinné číslo |
desetinné číslo s přesností nejméně 18 platných číslic |
| float | desetinné číslo |
32bitové číslo v plovoucí desetinné čárce |
| double | desetinné číslo |
64bitové číslo v plovoucí desetinné čárce |
| duration | délka časového intervalu |
ukázka reprezentuje interval o délce jeden rok, dva měsíce, tři dny, deset hodin a třicet minut |
| dateTime | datum a čas |
údaj je ve formátu ISO8601 a může obsahovat i časovou zónu |
| time | čas |
časový údaj ve formátu ISO8601; může obsahovat časovou zónu |
| date | datum |
datum ve formátu ISO8601, tj. rok-měsíc-den |
| gYearMonth | měsíc v daném roce |
ukázka reprezentuje září 1975 |
| gYear | rok | 2005 |
| gMonthDay | den v daném měsíci |
hodí se pro zachycení datumu, který se každý rok opakuje; ukázka např. reprezentuje Štědrý večer |
| gDay | určitý den v měsíci |
hodí se pro zachycení dne, ve kterém se každý měsíc něco opakuje; ukázka může například reprezentovat, že výplata je vždy dvanáctého |
| gMonth | určitý měsíc v roce |
ukázka reprezentuje měsíc květen |
| hexBinary | binární data |
binární data jsou zakódována tak, že každému bajtu odpovídají dva znaky reprezentující hodnotu bajtu v šestnáctkové soustavě |
| base64Binary | binární data |
binární data jsou zakódována metodou Base64 |
| anyURI | adresa URI |
jakákoliv URI adresa; může být absolutní i relativní |
| NOTATION | notace externích dat | v praxi téměř nepoužívaný typ, který byl do WXS převzat z DTD |
| normalizedString | normalizovaný řetězec znaků |
před kontrolou dalších integritních omezení jsou v řetězci konce řádků a tabulátory nahrazeny mezerou |
| token | ještě více normalizovaný řetězec znaků |
před kontrolou dalších integritních omezení jsou v řetězci konce řádků a tabulátory nahrazeny mezerou, opakující se mezery nahrazeny mezerou jedinou a jsou odstraněny mezery na začátku a konci řetězce |
| language | jazykový kód |
kód identifikující jazyk |
| NMTOKEN | typ byl převzat z DTD kvůli zpětné kompatibilitě; lze jej používat pouze pro atributy | |
| NMTOKENs | typ byl převzat z DTD kvůli zpětné kompatibilitě; lze jej používat pouze pro atributy | |
| Name | jméno |
jméno musí splňovat pravidla XML pro názvy elementů/atributů |
| NCName | jméno bez dvojtečky |
podobné jako typ |
| ID | unikátní identifikátor |
převzatý z DTD kvůli zpětné kompatibilitě |
| IDREF | odkaz na identifikátor |
převzatý z DTD kvůli zpětné kompatibilitě |
| IDREFS | odkazy na několik identifikátorů |
převzatý z DTD kvůli zpětné kompatibilitě |
| ENTITY | odkaz na externí binární entitu | převzatý z DTD kvůli zpětné kompatibilitě; může se použít pouze pro definici atributu |
| ENTITIES | odkazy na externí binární entity | převzatý z DTD kvůli zpětné kompatibilitě; může se použít pouze pro definici atributu |
| integer | celé číslo | -17, 0,
65542 |
| nonPositiveInteger | nekladné celé číslo |
celé číslo menší nebo rovné 0 |
| negativeInteger | záporné celé číslo |
celé číslo menší než 0 |
| long | celé číslo |
číslo je v rozsahu od -9223372036854775808 do 9223372036854775807, což odpovídá 64bitovému celému číslu |
| unsignedLong | nezáporné celé číslo |
číslo je v rozsahu od 0 do 18446744073709551615, což odpovídá 64bitovému celému číslu |
| int | celé číslo |
číslo je v rozsahu od -2147483648 do 2147483647, což odpovídá 32bitovému celému číslu |
| unsignedInt | nezáporné celé číslo |
číslo je v rozsahu od 0 do 4294967295, což odpovídá 32bitovému celému číslu |
| short | celé číslo |
číslo je v rozsahu od -32768 do 32767, což odpovídá 16bitovému celému číslu |
| unsignedShort | nezáporné celé číslo |
číslo je v rozsahu od 0 do 65535, což odpovídá 16bitovému celému číslu |
| byte | celé číslo |
číslo je v rozsahu od -128 do 127, což odpovídá 8bitovému celému číslu |
| unsignedByte | nezáporné celé číslo |
číslo je v rozsahu od 0 do 255, což odpovídá 8bitovému celému číslu |
| nonNegativeInteger | nezáporné celé číslo |
celé číslo větší nebo rovné 0 |
| positiveInteger | kladné celé číslo |
celé číslo větší než 0 |
Vyžadujeme-li však v aplikacích striktnější kontrolu dat, musíme si od zabudovaných typů odvodit vlastní typy. Nejběžnějším způsobem odvození je restrikce, kdy pomocí integritních omezení zúžíme obor přípustných hodnot. Kromě toho lze odvozovat nové typy vytvořením seznamu a sjednocením typů.
Nejpoužívanějším typem odvození nového typu je bezesporu restrikce. Na existující datový typ můžeme najednou aplikovat několik integritních omezení a tak zúžit přípustné hodnoty.
Podívejme se nejprve na integritní omezení použitelná pro
textové řetězce. Nejjednodušším z nich je
length, které umožňuje definovat přesnou délku
řetězce. Nový datový typ pro PSČ tak můžeme snadno odvodit ze
zabudovaného typu pro řetězce:
w
x
s<xs:simpleType name="PSČType"> <xs:restriction base="xs:string"> <xs:length value="6"/> </xs:restriction> </xs:simpleType>
Element simpleType slouží
k definici nového jednoduchého datového typu. Atribut name pak nese jméno nového
typu. Element restriction říká, že
odvození probíhá právě restrikcí od typu uvedeného v atributu
base (v našem
případě odvozujeme od běžného textového řetězce). Uvnitř elementu
restriction pak uvádíme všechna omezení,
v našem případě jen omezení na přesnou délku řetězce.
Nově definovaný typ můžeme použít při definici elementů a atributů nebo při definici dalších z něj odvozených typů. Nově definované typy se při vytváření elementů používají stejně jako zabudované typy:
w
x
s<xs:element name="psc" type="PSČType"/>
Mezi další omezení aplikovatelná na řetězcové typy patří
minimální (minLength) a maximální délka
(maxLength).
w
x
s<xs:simpleType name="jménoType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="15"/> </xs:restriction> </xs:simpleType>
Můžeme rovněž určit výčet přípustných hodnot pro datový typ:
w
x
s<xs:simpleType name="kódMěnyType"> <xs:restriction base="xs:string"> <xs:enumeration value="CZK"/> <xs:enumeration value="EUR"/> <xs:enumeration value="USD"/> </xs:restriction> </xs:simpleType>
Výčet hodnot lze použít pro všechny datové typy, ne jen pro řetězce.
Velmi silným nástrojem jsou regulární výrazy, které umožňují
zapsání masky, jíž musí hodnota vyhovět. Pro zápis omezení na základě
regulárního výrazu se používá element pattern. XML schémata používají podobnou syntaxi
regulárních výrazů jako jazyk Perl. K této syntaxi se za chvíli ještě
vrátíme.
w
x
s<xs:simpleType name="PSČType"> <xs:restriction base="xs:string"> <xs:pattern value="\d{3} \d{2}"/> </xs:restriction> </xs:simpleType>
U číselných typů můžeme omezit přípustné hodnoty zdola
(minInclusive, minExclusive)
i shora (maxInclusive,
maxExclusive). Navíc lze definovat celkový počet
platných číslic (totalDigits) a počet míst za
desetinnou čárkou (fractionDigits).
w
x
s<xs:simpleType name="částkaType"> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0"/> <xs:maxExclusive value="1000000"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType>
Chceme-li pro nějaký element nebo atribut použít vlastní datový typ, nemusíme jej ve schématu přímo deklarovat. Lze používat i anonymní datové typy, které definují uživatelský typ pouze pro jeden element či atribut a nejde se na ně odkazovat z jiných definic. Příklad s definicí elementu pro PSČ tak můžeme alternativně zapsat jako:
w
x
s<xs:element name="psc"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:length value="6"/> </xs:restriction> </xs:simpleType> </xs:element>
Regulární výrazy umožňují efektivním způsobem omezit hodnoty,
které lze použít jako hodnoty pro uživatelsky vytvořený datový
typ. Při definici typů můžeme uvést několik omezení pattern, alespoň jednomu z nich pak musí vyhovět
hodnota uvedená v dokumentu.
w
x
s<xs:simpleType name="pohlaví"> <xs:restriction base="xs:string"> <xs:pattern value="muž"/> <xs:pattern value="žena"/> </xs:restriction> </xs:simpleType>
Na výše uvedenou definici samozřejmě nemusíme používat regulární výrazy, na to by nám stačil i prostý výčet. Silou regulárních výrazů je možnost používat speciální obecné vzory, kterým vyhoví velké množství hodnot v určitém tvaru.
Poznámka
Regulárnímu výrazu ve WXS musí vždy vyhovět celá hodnota, ne jen
její část, jak je to běžné například pro perlové regulární
výrazy. Ekvivalentní perlový výraz by se v našem případě musel napsat
jako ^muž$.
Za normálních okolností se každý znak v regulárním výrazu musí právě jednou vyskytovat i v testované hodnotě. Toto chování však můžeme jednoduše ovlivnit tím, že znakem uvedeme indikátor počtu opakování.
Tabulka 3.2. Opakování znaku v regulárním výrazu
| Znak | Význam |
|---|---|
? | Předchozí znak se nemusí v testované hodnotě vyskytovat
(odpovídá {0,1}). |
+ | Předchozí znak se musí v testované hodnotě vyskytovat alespoň jednou
(odpovídá {1,}). |
* | Předchozí znak se může v testované hodnotě vyskytovat kolikrát chce
(odpovídá {0,}). |
{ | Předchozí znak se musí v testované hodnotě vyskytovat nejméně
m-krát a nejvíce n-krát. |
{ | Předchozí znak se musí v testované hodnotě vyskytovat nejméně
n-krát. |
{ | Předchozí znak se musí v testované hodnotě vyskytovat právě
n-krát. |
Řetězec, který začíná dvěma písmeny ‚a‘, za kterými
se opakuje libovolný počet písmen ‚b‘ (minimálně však
jedno) a na konci může končit znakem ‚c‘, tak můžeme
popsat pomocí výrazu a{2}b+c?.
Jak jsme viděli, některé znaky jako ‚?‘ nebo
‚{‘ mají ve výrazu speciální význam. Pokud chceme
tyto znaky ve výrazu zapsat v jejich původním významu, musíme použít
jejich přepis, který začíná zpětným lomítkem.
Tabulka 3.3. Zápis speciálních znaků v regulárním výrazu
| Znak | Přepis |
|---|---|
| konec řádky (LF) | \n |
| konec řádky (CR) | \r |
| tabulátor | \t |
\ | \\ |
| | \| |
. | \. |
- | \- |
^ | \^ |
? | \? |
* | \* |
+ | \+ |
{ | \{ |
} | \} |
( | \( |
) | \) |
[ | \[ |
] | \] |
Znak ‚.‘ má speciální význam – zastupuje
libovolný znak (s výjimkou znaků konce řádky). Například výrazu
.* vyhoví jakýkoliv řetězec i prázdný,
.+ zase vyhoví jakýkoliv řetězec, který má alespoň
jeden znak.
Můžeme tak například jednoduše definovat typ, který zahrne jen sudá čísla (končí na 0, 2, 4, 6 nebo 8).
w
x
s<xs:simpleType name="sudéČíslo"> <xs:restriction base="xs:int"> <xs:pattern value=".*0"/> <xs:pattern value=".*2"/> <xs:pattern value=".*4"/> <xs:pattern value=".*6"/> <xs:pattern value=".*8"/> </xs:restriction> </xs:simpleType>
Třídy znaků jsou asi vůbec nejsilnější zbraní regulárních
výrazů. Třída znaků vždy zastupuje celou skupinu znaků, které mají
nějakou společnou vlastnost. Například třída \d
zastupuje jakoukoliv číslici 0–9. Výraz pro poštovní směrovací číslo
tak můžeme zapsat jako \d\d\d \d\d,
resp. \d{3} \d{2}. Podobných tříd znaků máme
k dispozici několik. Základní třídy shrnuje tabulka 3.4 – „Základní třídy znaků“.
Tabulka 3.4. Základní třídy znaků
| Třída | Popis |
|---|---|
\s | Mezery (kromě klasické mezery zahrnuje i tabulátory a znaky konce řádku). |
\S | Všechny znaky kromě mezer. |
\d | Číslice 0–9 včetně číslic v dalších abecedách, např. ٠١٢٣٤٥٦٧٨٩ (arabsky), ०१२३४५६७८९ (devanagari). |
\D | Všechny znaky kromě číslic. |
\w | Znaky, které tvoří slovo (tj. všechny znaky kromě těch, které jsou v Unicode definované jako oddělovače, interpunkce nebo ostatní). |
\W | Znaky, které netvoří slovo. |
\i | Znaky, kterými může v XML začínat jméno (tj. všechna písmena
a znaky ‚-‘ a ‚:‘[a]). |
\I | Znaky, kterými nemůže v XML začínat jméno. |
\c | Znaky, které může obsahovat jméno elementu/atribut v XML. |
\C | Znaky, které nemůže obsahovat jméno elementu/atribut v XML. |
[a] Jen připomeňme, že samotné XML dovoluje použít dvojtečku ve jménu elementu/atributu, nicméně v praxi se to nedělá, protože tento znak odděluje prefix jmenného prostoru od lokálního jména. | |
Kromě základních tříd znaků můžeme v regulárních výrazech používat unicodové třídy znaků a bloky unicodových znaků. Unicodové třídy zastupují vždy celou skupinu znaků se stejným použitím – např. číslice, interpunkce – bez ohledu na to, do jaké patří abecedy. Oproti tomu bloky unicodových znaků vždy obsahují znaky patřící do nějaké abecedy – např. latinky, azbuky, devanagari.[2]
Na unicodovou třídu znaků se odvoláme zápisem
\p{. Na blok znaků
se odvoláme zápisem
jméno}\p{Is. Můžeme se
odkázat i na všechny znaky, které do dané třídy nebo bloku znaků
nepatří, stačí použít velké písmeno
jméno}\P{.jméno}
Tabulka 3.5. Unicodové třídy znaků
| Název třídy | Popis |
|---|---|
| Písmena | |
| L | Všechna písmena |
| Lu | Velká písmena |
| Ll | Malá písmena |
| Lt | Písmena titulku (velmi speciální případ, má smysl pro některé unicodové znaky, které reprezentují složení dvou znaků, např. Dž) |
| Lm | Modifikátor písmene (používá se například pro upřesnění výslovnosti předchozího písmene) |
| Lo | Ostatní písmena (zahrnuje především písmena abeced, které nerozlišují malá a velká písmena – např. arabština, hebrejština, různé indické a asijské abecedy) |
| Znaménka | |
| M | Všechna znaménka |
| Mn | Znaménka nezabírající místo (zejména diakritická znaménka, která jde kombinovat s dalšími znaky) |
| Mc | Znaménka zabírající místo (využívající se zejména v indických skriptech) |
| Me | Ohraničující znaménka (např. ⃝, které se umí zkombinovat s předchozím znakem a obalit ho) |
| Číslice | |
| N | Všechny číslice |
| Nd | Desítkové číslice |
| Nl | Číslice zapisované písmeny (například římské číslice – ⅯⅯⅥ) |
| No | Ostatní číslice (například horní indexy, zlomky – ¼, ², ৹) |
| Interpunkce | |
| P | Veškerá interpunkce |
| Pc | Spojky (například podtržítko) |
| Pd | Pomlčky (například -, –, —) |
| Ps | Otevírací interpunkce (například všechny levé závorky) |
| Pe | Uzavírací interpunkce (například všechny pravé závorky) |
| Pi | Otevírací uvozovky (ale i apostrof, francouzská uvozovka apod. – «‚„) |
| Pf | Uzavírací uvozovky (ale i apostrof, francouzská uvozovka apod. – »‘“) |
| Po | Ostatní interpunkce (například otazník a vykřičník) |
| Oddělovače | |
| Z | Všechny oddělovače |
| Zs | Mezery |
| Zl | Oddělovač řádky |
| Zp | Oddělovač odstavce |
| Symboly | |
| S | Všechny symboly |
| Sm | Matematické symboly (například ±×↑∀∋√∞) |
| Sc | Měnové symboly (například $¢£¤¥€) |
| Sk | Modifikátory (například samostatná diakritická znaménka) |
| So | Ostatní symboly (například §©®°¶҂) |
| Ostatní znaky | |
| C | Všechny ostatní znaky |
| Cc | Řídící znaky (například tabulátor, znaky CR a LF) |
| Cf | Formátovací znaky (například indikátor možného rozdělení slova) |
| Co | Znaky v privátní oblasti Unicode |
| Cn | Dosud nezařazené znaky |
Tabulka 3.6. Bloky unicodových znaků
|
Se znalostí těchto tříd si klidně můžeme definovat typ, který
akceptuje částku včetně měny (např. 123.5 $):
w
x
s<xs:simpleType name="částkaVčetněMěny"> <xs:restriction base="xs:token"> <xs:pattern value="\d+\.?\d*\s*\p{Sc}"/> </xs:restriction> </xs:simpleType>
Třídy znaků si můžeme definovat i vlastní. Třída se definuje
jako množina znaků zapsaná do hranatých závorek. Například zápis
[abc] definuje třídu, která zastupuje libovolný ze
znaků ‚a‘, ‚b‘ a ‚c‘.
Pomocí znaku ‚-‘ můžeme
jednoduše definovat interval znaků. Například všechna písmena od ‚a‘
do ‚z‘ můžeme zapsat jako [a-z], číslice od 0 do
9 zase jako [0-9].
K uživatelsky definované třídě lze vytvořit doplněk, pokud jako
první znak ve hranatých závorkách použijeme
‚^‘. Všechny znaky kromě ‚a‘, ‚b‘ a ‚c‘ můžeme
definovat jako [^abc], všechny znaky kromě písmen
‚a‘ až ‚z‘ pak jako [^a-z].
Uvnitř hranatých závorek se můžeme odvolávat i na ostatní třídy
znaků. Můžeme například definovat výraz, kterému vyhoví jen řecká
písmena, číslice a matematické symboly –
[\p{IsGreek}0-9\p{Sm}]. Uživatelské třídy znaků jde
samozřejmě kombinovat s dalšími konstrukcemi regulárních výrazů. Pro
poštovní směrovací číslo tak můžeme vytvořit přesnější regulární
výraz, který nám nedovolí zadat číslo třeba v devanagari, ale jen
skutečně pomocí číslic 0–9: [0-9]{3}
[0-9]{2}.
Hranaté závorky nedefinují nic jiného než množinu složenou ze
znaků, případně její doplněk (jeli první znak
‚^‘). Uživatelskou třídu znaků lze definovat
i pomocí množinového rozdílu, slouží k tomu zápis
[. Můžeme
tak snadno definovat regulární výraz, kterému vyhoví jen písmena řecké
abecedy s výjimkou znaků ‚α‘, ‚β‘ a ‚γ‘.A-[B]]
w
x
s<xs:simpleType name="řeckéSlovoBezAlfaBetaGama"> <xs:restriction base="xs:string"> <xs:pattern value="[\p{IsGreek}-[αβγ]]+"></xs:pattern> </xs:restriction> </xs:simpleType>
V regulárních výrazech ještě můžeme používat znak
‚|‘, který umožňuje zadat několik variant, kterým
mají testované hodnoty vyhovět. Naše dřívější příklady tak můžeme
zjednodušit na:
w
x
s<xs:simpleType name="pohlaví"> <xs:restriction base="xs:string"> <xs:pattern value="muž|žena"/> </xs:restriction> </xs:simpleType>
w
x
s<xs:simpleType name="sudéČíslo"> <xs:restriction base="xs:int"> <xs:pattern value=".*0|.*2|.*4|.*6|.*8"/> </xs:restriction> </xs:simpleType>
Pomocí závorek pak můžeme dílčí regulární výrazy
kombinovat a vytvářet složitější. Poslední příklad můžeme zapsat také
jako .*(0|2|4|6|8) nebo
.*[02468].
Jde pak vytvářet v podstatě libovolně složité výrazy. Následující příklad definuje typ, kterému vyhoví jakýkoliv seznam slov oddělených čárkami nebo středníky.
w
x
s<xs:simpleType> <xs:restriction base="xs:string"> <xs:pattern value="\w+\s*([,;]\s*\w+)*"/> </xs:restriction> </xs:simpleType>
Příklad 3.1. Využití regulárních výrazů –
wxs/re.xsd
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="doc"> <xs:complexType> <xs:sequence> <xs:element name="řeckyBezAlfaBetaGama" maxOccurs="unbounded"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:pattern value="[\p{IsGreek}-[αβγ]]+"></xs:pattern> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="seznamSlovOddělenýČárkamiNeboStředníky" maxOccurs="unbounded"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:pattern value="\w+\s*([,;]\s+\w+)*"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="psčJakoToken" maxOccurs="unbounded"> <xs:simpleType> <xs:restriction base="xs:token"> <xs:pattern value="[0-9]{3} [0-9]{2}"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="psčJakoString" maxOccurs="unbounded"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:pattern value="[0-9]{3} [0-9]{2}"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="rč" maxOccurs="unbounded"> <xs:simpleType> <xs:restriction base="xs:token"> <xs:pattern value="[0-9]{6}/[0-9]{3,4}"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="rčLépeKontrolované" maxOccurs="unbounded"> <xs:simpleType> <xs:restriction base="xs:token"> <xs:pattern value="[0-9]{2}([05][1-9]|[16][0-2])([012][0-9]|3[01])/[0-9]{3,4}"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="email" maxOccurs="unbounded"> <xs:simpleType> <xs:restriction base="xs:token"> <xs:pattern value="[!-~-[()<>@;:\\"\[\]]]+@[!-~-[()<>@;:\\"\[\]]]+"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="částkaVčetněMěny" maxOccurs="unbounded"> <xs:simpleType> <xs:restriction base="xs:token"> <xs:pattern value="\d+\.?\d*\s*\p{Sc}"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="sudéČíslo" maxOccurs="unbounded"> <xs:simpleType> <xs:restriction base="xs:int"> <xs:pattern value=".*[02468]"/> </xs:restriction> </xs:simpleType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
Pro správné pochopení integritních omezení je potřeba si uvědomit, že hodnota, kterou kontrolují, nemusí být stejná jako hodnota zapsaná přímo do dokumentu XML.
Jak ukazuje obrázek 3.2 – „Jak se text z dokumentu XML přemění na hodnotu“ údaj
uložený v dokumentu XML se nejprve normalizuje. Při této normalizaci
se bílé znaky jako konce řádky a tabulátory nahradí
mezerou. Poté se oříznou veškeré mezery na začátku a konci hodnoty
a vícenásobný výskyt znaku mezera se nahradí mezerou jedinou. Tato
normalizace se provádí vždy s výjimkou typů string,
normalizedString a od nich odvozených uživatelských
typů. Pro typ string se neprovádí vůbec žádná
normalizace a pro normalizedString se pouze znaky
konce řádků a tabulátory převedou na mezery.
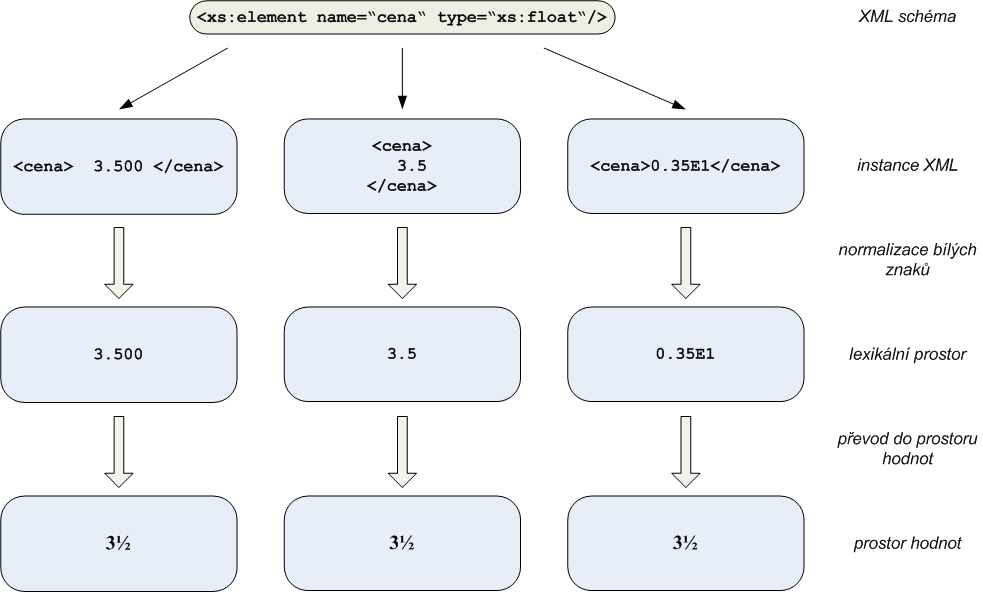
Po normalizaci údaje z dokumentu XML získáme jeho lexikální
reprezentaci. Nad tímto lexikálním prostorem pracuje integritní
omezení pomocí regulárního výrazu (pattern). Všechny ostatní kontroly, jako počet
desetinných míst, přípustný rozsah hodnot apod., se provádějí
až nad prostorem hodnot. Ten obsahuje již abstraktní reprezentaci
původního údaje. Na obrázku 3.2 – „Jak se text z dokumentu XML přemění na hodnotu“ je
tak vidět, jak se původně tři různé zápisy nakonec převedly na stejnou
hodnotu 3½.
Ačkoliv je ve většině případů lepší veškeré struktury značkovat pomocí elementů nebo atributů, může se někdy hodit strukturu nevyznačovat explicitně přímo prostředky jazyka XML. WXS podporují jako datový typ seznamy hodnot oddělené mezerami (obecně bílými znaky). Tento seznam se může skládat z několika hodnot stejného datového typu.
Pro seznamy si musíme vytvořit vlastní datový typ, který je
definován pomocí list a tento typ pak
použít při definici elementu nebo atributu.
w
x
s<xs:simpleType name="seznamČísel"> <xs:list itemType="xs:int"/> </xs:simpleType> <xs:element name="čísla" type="seznamČísel"/>
V dokumentu pak můžeme používat zápisy jako
<čísla>1 2 3 4 5 6 42 999 17</čísla>
Typ položek seznamu nemusíme určovat jen pomocí atributu
itemType, ale můžeme
použít vnoření definice typu:
w
x
s<xs:simpleType name="seznamČísel"> <xs:list> <xs:simpleType> <xs:restriction base="xs:int"/> </xs:simpleType> </xs:list> </xs:simpleType>
Pro celý seznam lze nastavit integritní omezení omezující délku seznamu. Musíme si však vytvořit nový seznam, odvozený restrikcí od existujícího, a integritní omezení nastavit na tom nově vytvářeném. Následující příklad ukazuje definici typu pro seznam s přesně třemi hodnotami:
w
x
s<xs:simpleType name="míry"> <xs:restriction base="seznamČísel"> <xs:length value="3"/> </xs:restriction> </xs:simpleType>
WXS umožňují vytvořit datový typ, který akceptuje hodnoty
několika jiných různých datových typů. Předpokládejme, že chceme
definovat element věk tak, aby akceptoval číselné
hodnoty a zároveň hodnotu „neuvedeno“:
<věk>30</věk> <věk>neuvedeno</věk>
Stačí využít konstrukci union
a sjednotit datový typ pro kladná čísla s typem pro řetězec
„neuvedeno“:
w
x
s<xs:element name="věk"> <xs:simpleType> <xs:union> <xs:simpleType> <xs:restriction base="xs:positiveInteger"/> </xs:simpleType> <xs:simpleType> <xs:restriction base="xs:token"> <xs:enumeration value="neuvedeno"/> </xs:restriction> </xs:simpleType> </xs:union> </xs:simpleType> </xs:element>
Komplexní typy slouží k modelování struktury dokumentu, protože se mohou skládat z elementů a atributů. U elementů můžeme určit v jakém pořadí se mají vyskytovat, kolikrát se mohou opakovat, zda jsou povinné či volitelné.
Komplexní typ se definuje pomocí elementu
complexType. Podobně jako u jednoduchých typů
můžeme definovat komplexní typ samostatně, aby pak šel používat
opakovaně pro různé elementy. Následující příklad ukazuje, jak
definovat elementy odberatel a
dodavatel tak, že mají stejný obsah, právě pomocí
společně použitého uživatelsky definovaného komplexního typu
subjektType.
w
x
s<xs:element name="faktura"> <xs:complexType> <xs:sequence> <xs:element name="odberatel" type="subjektType"/> <xs:element name="dodavatel" type="subjektType"/> ... </xs:sequence> </xs:complexType> </xs:element> <xs:complexType name="subjektType"> <xs:sequence> <xs:element name="nazev" type="xs:string" /> <xs:element name="adresa" type="xs:string" /> <xs:element name="ico" type="xs:string" /> <xs:element name="dic" type="xs:string" /> </xs:sequence> </xs:complexType>
Druhou možností je použít complexType přímo
v definici elementu. Takto je v předchozím příkladě
definován obsah elementu faktura.
Uvnitř elementu complexType pak
můžeme použít další elementy sequence,
choice a all (tzv. kompozitory). Elementy definované
uvnitř sequence se musí v dokumentu
vyskytovat v definovaném pořadí. Oproti tomu all říká, že elementy se mohou vyskytovat
v libovolném pořadí. Konečně choice
říká, že se v dokumentu může vyskytnout jen jeden z obsažených
elementů. Tyto elementy lze do sebe podle potřeby zanořovat
(s výjimkou all) a tak modelovat
složitější situace.
Následující příklad definuje schéma pro článek, který má název, libovolný počet autorů a pak se v něm podle potřeby vyskytuje libovolný počet obrázků anebo odstavců.
w
x
s<xs:element name="clanek"> <xs:complexType> <xs:sequence> <xs:element name="nazev" type="xs:string"/> <xs:element name="autor" type="xs:string" minOccurs="0" maxOccurs="unbounded"/> <xs:choice minOccurs="1" maxOccurs="unbounded"> <xs:element name="odstavec" type="xs:string"/> <xs:element name="obrazek" type="xs:base64Binary"/> </xs:choice> </xs:sequence> </xs:complexType> </xs:element>
Příklad také demonstruje, jakým způsobem lze určovat počet
výskytů elementu nebo celé jejich skupiny. Slouží k tomu atributy
minOccurs a maxOccurs. Jejich standardní
hodnota je jedna. Pro nekonečno se používá identifikátor
unbounded.
Nejpoužívanější konstrukcí uvnitř komplexního typu je sekvence
elementů (sequence). Tento kompozitor říká, že
v něm obsažené definice elementů (případně dalších vnořených
struktur) se musí v dokumentu vyskytovat přesně v tom
pořadí, jak jsou uvedeny. Počet výskytů jednotlivých elementů je možné
ovlivnit právě pomocí atributů minOccurs a maxOccurs. Implicitně mají oba hodnotu
jedna, což odpovídá povinnému výskytu elementu.
Následující příklad definuje element pro uložení článku, který má povinný název, nepovinného autora a dále následuje libovolný počet odstavců, přičemž vždy musí být uveden alespoň jeden odstavec.
Příklad 3.2. Sekvence elementů
<článek> <název>Ukázka</název> <autor>Pepa</autor> <odstavec>...</odstavec> <odstavec>...</odstavec> </článek>
w
x
s<xs:element name="článek"> <xs:complexType> <xs:sequence> <xs:element name="název" type="xs:string"/> <xs:element name="autor" type="xs:string" minOccurs="0"/> <xs:element name="odstavec" type="xs:string" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> </xs:element>
Chceme-li říci, že na určitém místě dokumentu se může vyskytovat
jeden z několika elementů, použijeme k tomu kompozitor
choice. Na jeho místě se pak může vyskytnout
jakýkoliv element definovaný uvnitř této konstrukce.
Následující příklad ukazuje schéma, které modeluje seznam osob. U každé osoby přitom musí být uveden jeden ze tří identifikátorů – rodné číslo, číslo pasu nebo číslo sociálního pojištění.
Příklad 3.3. Výběr jednoho z elementů – wxs/choice.xsd
<osoby>
<osoba>
<jméno>Pepa Tuzemec</jméno>
<RČ>681203/0123</RČ>
</osoba>
<osoba>
<jméno>Pepa Cizinec</jméno>
<pas>1234567</pas>
</osoba>
<osoba>
<jméno>Pepa Rozvědčík</jméno>
<SSN>987654321</SSN>
</osoba>
</osoby>w
x
s<xs:element name="osoby"> <xs:complexType> <xs:sequence> <xs:element name="osoba" maxOccurs="unbounded"> <xs:complexType> <xs:sequence> <xs:element name="jméno" type="xs:string"/> <xs:choice> <xs:element name="RČ" type="xs:string"/> <xs:element name="pas" type="xs:string"/> <xs:element name="SSN" type="xs:string"/> </xs:choice> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element>
V mnoha případech nám nezáleží na pořadí, v jakém jsou
nějaké elementy uvedeny a nechceme uživatele zbytečně nutit
k tomu, aby dodržoval nějaké konkrétní pořadí. V tomto
případě se obsah komplexního typu definuje pomocí kompozitoru
all. Nepříjemným omezením je, že
u jednotlivých elementů ve skupině all můžeme
počet jejich výskytů definovat pouze v rozmezí od nuly do jedné.
Větší počet výskytů není dovolen, protože by se příliš zesložitil
model obsahu.
Následující příklad ukazuje definici elementu
osoba, který může obsahovat jméno a příjmení
v libovolném pořadí, navíc se v elementu může vyskytovat
i titul.
Příklad 3.4. Elementy v libovolném pořadí – wxs/all.xsd
<osoba> <jméno>Jan</jméno> <příjmení>Novák</příjmení> </osoba> <osoba> <příjmení>Novák</příjmení> <jméno>Jan</jméno> </osoba> <osoba> <titul>Ing.</titul> <jméno>Jan</jméno> <příjmení>Novák</příjmení> </osoba> <osoba> <jméno>Jan</jméno> <příjmení>Novák</příjmení> <titul>CSc.</titul> </osoba>
w
x
s<xs:element name="osoba"> <xs:complexType> <xs:all> <xs:element name="jméno" type="xs:string"/> <xs:element name="příjmení" type="xs:string"/> <xs:element name="titul" type="xs:string" minOccurs="0"/> </xs:all> </xs:complexType> </xs:element>
Uvedené schéma však není schopno zachytit případy, kdy má jeden
člověk tituly dva, jeden před jménem a druhý za jménem, protože uvnitř
all nejde elementům nastavit maxOccurs na větší hodnotu než jedna.
Vzhledem k tomu, že možnost kombinování all
s ostatními konstrukty je velmi omezená,[3] je potřeba se při řešení našeho problému obejít bez
all a ručně vypsat všechny kombinace elementů
v různém pořadí.
Příklad 3.5. Schéma pro osobu s tituly a se jménem a příjmením v libovolném pořadí
w
x
s<xs:element name="osoba"> <xs:complexType> <xs:sequence> <xs:element name="titul" type="xs:string" minOccurs="0"/> <xs:choice> <xs:sequence> <xs:element name="jméno" type="xs:string"/> <xs:element name="příjmení" type="xs:string"/> </xs:sequence> <xs:sequence> <xs:element name="příjmení" type="xs:string"/> <xs:element name="jméno" type="xs:string"/> </xs:sequence> </xs:choice> <xs:element name="titul" type="xs:string" minOccurs="0"/> </xs:sequence> </xs:complexType> </xs:element>
V textově zaměřených dokumentech jako jsou různé články,
dokumentace apod. často potřebujeme používat tzv. smíšený obsah (mixed
content). Je to situace, kdy může být text na stejné úrovni kombinován
s dalšími elementy. Typickým příkladem je element pro odstavec.
Ten může obsahovat jak přímo text, tak i další elementy pro
zvýraznění textu, vytváření odkazů apod. Definice smíšeného obsahu je
velmi jednoduchá. U definice komplexního typu elementu stačí
přidat atribut mixed
s hodnotou true.
Smíšený obsah v XML schématech funguje poněkud odlišně než
v DTD. V DTD smíšený obsah vždy automaticky implikuje, že
elementy na stejné úrovni jako text se mohou vyskytovat
v libovolném pořadí a opakovaně. V XML schématech smíšený
obsah říká, že text se může objevit kdekoliv mezi elementy, které
komplexní typ definuje. Smíšený obsah v klasickém slova smyslu se
proto musí definovat pomocí skupiny choice, která má libovolný počet výskytů a obalí
všechny elementy, které se mohou mísit s textem.
Příklad 3.6. Smíšený obsah – wxs/odstavce.xsd
<odstavec>Odstavce typicky obsahují <pojem>smíšený obsah</pojem>. Text se může střídat s <odkaz url="http://www.kosek.cz">odkazy</odkaz> a dalšími <pojem>elementy</pojem>.</odstavec> <odstavec>Odstavec může obsahovat i jen text.</odstavec> <odstavec><pojem>Nebo jen element.</pojem></odstavec>
w
x
s<xs:element name="odstavec"> <xs:complexType mixed="true"> <xs:choice minOccurs="0" maxOccurs="unbounded"> <xs:element name="pojem" type="xs:string"/> <xs:element name="odkaz"> <xs:complexType> <xs:simpleContent> <xs:extension base="xs:string"> <xs:attribute name="url" type="xs:anyURI"/> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> </xs:element>
Prázdné elementy jsou takové elementy, které nemají žádný obsah. V instanci dokumentu se zapisují jedním z následujících dvou způsobů:
<prazdny/> <prazdny></prazdny>
Prázdné elementy mají obvykle atributy. Atributy se musí
definovat jako součást komplexního typu. Např. pro element
img s atributem src
<img src="obrazek.png"/>
by definice elementu vypadala následovně
w
x
s<xs:element name="img"> <xs:complexType> <xs:attribute name="src" type="xs:anyURI"/> </xs:complexType> </xs:element>
Jedná se přitom o zkrácený zápis. Plná syntaxe (kterou samozřejmě nemusíte používat) vychází z idey, že elementu odebereme jeho obsah a přidáme k němu atribut.
w
x
s<xs:element name="img"> <xs:complexType> <xs:complexContent> <xs:restriction base="xs:anyType"> <xs:attribute name="src" type="xs:anyURI"/> </xs:restriction> </xs:complexContent> </xs:complexType> </xs:element>
Atribut je součástí komplexního typu a definuje se pomocí
elementu attribute:
w
x
s<xs:attribute name="vek" type="xs:positiveInteger"/>
U atributů můžeme určit nejen jejich jméno a typ, ale zda mají být povinné, jaká je jejich defaultní hodnota apod. Např.:
w
x
s<xs:attribute name="ident" type="xs:ID" use="required"/> <xs:attribute name="měna" type="xs:string" default="USD"/>
Atributy se uvádějí vždy až na konci komplexního typu. Jediným
složitějším případem je situace, kdy chceme atributy přidat
k elementu, který neobsahuje již další podelementy, ale má
jednoduchý datový typ. Výsledný zápis je pak poněkud krkolomný.
Představme si, že chceme definovat element cena,
který bude mít atribut měna pro uložení kódu měny.
<cena měna="USD">23.69</cena>
Chceme přitom využít dříve definované datové typy. V řeči XML schémat vypadá definice následovně:
w
x
s<xs:element name="cena"> <xs:complexType> <xs:simpleContent> <xs:extension base="částkaType"> <xs:attribute name="měna" type="kódMěnyType"/> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element>
Přeloženo do lidské řeči: Vytvoř komplexní typ, který vznikne
rozšířením jednoduchého obsahu s typem
částkaType o atribut měna. Obecně tedy definice elementu, který
má nějaký jednoduchý typ jako svůj obsah a kromě toho má další
atributy, vypadá:
w
x
s<xs:element name="cena"> <xs:complexType> <xs:simpleContent> <xs:extension base="typ_obsahu_elementu"> …definice atributů… </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element>
Pro dokonalé pochopení XML schémat, se musíme seznámit s lokálními a globálními deklaracemi a rozdílem mezi nimi.
Za globální se považují deklarace provedené na nejvyšší úrovni
schématu, přímo v elementu schema. Globálně deklarované elementy a datové
typy mají v některých ohledech speciální chování. Dokument vyhovující
schématu může začínat libovolným globálním elementem. Ve většině
schémat má proto smysl deklarovat jako globální pouze ten element,
který chceme použít jako obálku okolo celého dokumentu XML. O různých
možnostech, jak toho dosáhnout pojednává sekce 3.7 – „Přístupy k návrhu schématu“.
Jako ukázka nevhodného přístupu může sloužit následující schéma
faktury, ve kterém jsou jako globální deklarovány elementy
faktura a polozka. Validací tedy
projde nejen kompletní faktura, ale i jedna jediná položka.
Příklad 3.7. Schéma definující dva globální elementy –
wxs/faktura.xsd
w
x
s<?xml version="1.0" encoding="utf-8" ?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="urn:x-kosek:schemas:faktura:1.0" xmlns="urn:x-kosek:schemas:faktura:1.0" elementFormDefault="qualified"> <xs:element name="faktura"> <xs:complexType> <xs:sequence> <xs:element name="odberatel" type="subjektInfoTyp" /> <xs:element name="dodavatel" type="subjektInfoTyp" /> <xs:element ref="polozka" minOccurs="1" maxOccurs="unbounded" /> </xs:sequence> <xs:attribute name="cislo" type="cisloFakturyTyp" use="required" /> <xs:attribute name="vystaveni" type="xs:date" use="required" /> <xs:attribute name="splatnost" type="xs:date" use="required" /> <xs:attribute name="vystavil" type="xs:string" /> </xs:complexType> </xs:element> <xs:complexType name="subjektInfoTyp"> <xs:sequence> <xs:element name="nazev" type="xs:string" /> <xs:element name="adresa" type="xs:string" /> <xs:element name="ico" type="icoTyp" /> <xs:element name="dic" type="dicTyp" /> </xs:sequence> </xs:complexType> <xs:simpleType name="icoTyp"> <xs:restriction base="xs:string"> <xs:pattern value="\d{10}" /> </xs:restriction> </xs:simpleType> <xs:simpleType name="dicTyp"> <xs:restriction base="xs:string"> <xs:pattern value="\d{3}-\d{10}" /> </xs:restriction> </xs:simpleType> <xs:simpleType name="cisloFakturyTyp"> <xs:restriction base="xs:string"> <xs:pattern value="\d{4}/\d{3}" /> </xs:restriction> </xs:simpleType> <xs:element name="polozka"> <xs:complexType> <xs:sequence> <xs:element name="popis" type="xs:string" minOccurs="0" maxOccurs="1" /> <xs:element name="cena" type="částkaTyp" /> <xs:element name="dph" type="dphTyp" /> <xs:element name="ks" type="xs:positiveInteger" minOccurs="0" maxOccurs="1" /> </xs:sequence> </xs:complexType> </xs:element> <xs:simpleType name="částkaTyp"> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0" /> </xs:restriction> </xs:simpleType> <xs:simpleType name="dphTyp"> <xs:restriction base="xs:decimal"> <xs:enumeration value="22" /> <xs:enumeration value="5" /> </xs:restriction> </xs:simpleType> </xs:schema>
Na globálně deklarované typy a elementy se lze odvolávat z jiných schémat (viz 3.12.5 – „Schéma definující elementy v několika jmenných prostorech“). V další sekci uvidíme, že globálně a lokálně deklarované elementy mají i odlišné vlastnosti vzhledem ke jmenným prostorům.
Bývá dnes dobrým zvykem přiřadit každému nově vytvořenému
značkovacímu jazyku vlastní jmenný prostor, aby jej šlo snadno
identifikovat. Jmenný prostor, do něhož budou elementy patřit, se
určuje pomocí atributu targetNamespace u kořenového elementu
schématu. Z praktických důvodů se tento jmenný prostor obvykle
deklaruje i jako implicitní, abychom před naše elementy nemuseli
všude psát nějaký prefix.
XML schéma má jednu nepříjemnou vlastnost – do jmenného
prostoru patří jen globální elementy. Jsou to pouze ty elementy, které
jsou ve schématu definované na nejvyšší úrovni přímo pod elementem
schema. Předpokládejme například
následující schéma:
w
x
s<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="urn:x-kosek:schemas:pokus" xmlns="urn:x-kosek:schemas:pokus"> <xs:element name="a"> <xs:complexType> <xs:sequence> <xs:element name="b" type="xs:string"/> <xs:element name="c" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
Instance, která schématu vyhovuje, pak odporuje ustáleným praktikám pro tvorbu dokumentů XML. Můžeme ji zapsat buď jako:
<a xmlns="urn:x-kosek:schemas:pokus"> <b xmlns="">foo</b> <c xmlns="">bar</c> </a>
nebo
<p:a xmlns:p="urn:x-kosek:schemas:pokus"> <b>foo</b> <c>bar</c> </p:a>
Nepřehledný a nekonzistentní zápis je právě důsledkem toho, že
elementy b a c nepatří do
žádného jmenného prostoru. Každý element by přitom měl patřit do
nějakého jmenného prostoru. Toho můžeme dosáhnout tím, že pomocí
atributu elementFormDefault řekneme, že celé schéma
musí používat kvalifikované (rozuměj zařazené do nějakého jmenného
prostoru) elementy.
w
x
s<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="urn:x-kosek:schemas:pokus" xmlns="urn:x-kosek:schemas:pokus" elementFormDefault="qualified"> <xs:element name="a"> <xs:complexType> <xs:sequence> <xs:element name="b" type="xs:string"/> <xs:element name="c" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
S tímto schématem už můžeme vytvářet dokumenty, tak jak je zvykem.
<a xmlns="urn:x-kosek:schemas:pokus"> <b>foo</b> <c>bar</c> </a> <p:a xmlns:p="urn:x-kosek:schemas:pokus"> <p:b>foo</p:b> <p:c>bar</p:c> </p:a>
Ve skutečnosti je možné u každého elementu nebo atributu určit,
zda má nebo nemá patřit do cílového jmenného prostoru. Slouží k tomu
atribut form, jehož
použití ukazuje následující příklad, který rovněž definuje všechny tři
elementy v jednom jmenném prostoru.
w
x
s<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="urn:x-kosek:schemas:pokus" xmlns="urn:x-kosek:schemas:pokus"> <xs:element name="a"> <xs:complexType> <xs:sequence> <xs:element name="b" type="xs:string" form="qualified"/> <xs:element name="c" type="xs:string" form="qualified"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
V praxi se však příslušenství elementů (případně atributů) do
jmenného prostoru obvykle definuje globálně a využívají se proto
atributy elementFormDefault a attributeFormDefault.
Použití jmenných prostorů ve schématech přináší ještě jednu záludnost. Do cílového jmenného prostoru patří nejen globálně deklarované elementy, ale i typy. Odvoláváme-li se pak při definici elementu nebo atributu na uživatelsky definovaný typ, musíme jej určit pomocí jeho kvalifikovaného jména. Dosáhnout tohoto cíle lze dvě způsoby. První spočívá v deklaraci prefixu pro cílový jmenný prostor.
Příklad 3.8. Odkaz na typ s využitím prefixu –
src/ns-typy1.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://example.org/ns" xmlns:tns="http://example.org/ns" elementFormDefault="qualified"> <xs:element name="root" type="tns:mujTyp"/> <xs:simpleType name="mujTyp"> <xs:restriction base="xs:string"/> </xs:simpleType> </xs:schema>
Druhá možnost využívá toho, že XML schémata rozšiřují dopad výchozího jmenného prostoru ze jmen elementů i na jména datových typů (samozřejmě pouze uvnitř schématu, změna se netýká instancí). Předchozí schéma tak můžeme napsat i následujícím způsobem, který je většinou i běžnější.
Příklad 3.9. Odkaz na typ s využitím výchozího jmenného prostoru –
src/ns-typy2.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://example.org/ns" xmlns="http://example.org/ns" elementFormDefault="qualified"> <xs:element name="root" type="mujTyp"/> <xs:simpleType name="mujTyp"> <xs:restriction base="xs:string"/> </xs:simpleType> </xs:schema>
Chceme-li přímo v dokumentu XML určit, kde může parser
najít schéma například pro účely validace, musíme k tomu použít
speciální globální atributy patřící do jmenného prostoru
http://www.w3.org/2001/XMLSchema-instance.
Nepoužíváme-li jmenné prostory, stačí do atributu noNamespaceSchemaLocation uvést
URL adresu, na které se nachází schéma. Můžeme použít samozřejmě
i relativní URL a jednoduše se tak odkázat na soubor se
schématem, který je ve stejném adresáři jako dokument.
<dokument xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="dokument.xsd"> ... </dokument>
Používáme-li jmenné prostory, musíme použít atribut schemaLocation. Ten může obsahovat několik
dvojic hodnot URI jmenného prostoru a umístění schématu. Hodnoty jsou
přitom oddělené mezerami nebo jinými bílými znaky.
<dokument xmlns="urn:x-kosek:schemas:dokument:1.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:x-kosek:schemas:dokument:1.0 dokument.xsd"> ... </dokument>
Některé novější aplikace již podporují novou instrukci
<?xml-model?>. Ta umožňuje připojit jakékoliv
schéma bez nutnosti používat speciální atributy.
<?xml-model href="dokument.xsd"?>
<dokument>
...
</dokument>Obecně však tento způsob připojování schématu nelze
doporučit. Hodí se pro účely testování a různých hrátek se
schématy. V praxi bychom však atributy schemaLocation a noNamespaceSchemaLocation neměli
používat. Schéma vhodné pro validaci by si měla vybrat sama aplikace,
která validaci provádí jako součást zpracování dokumentu. Můžeme tak
vždy určit jedno pevné schéma, nebo schéma vybrat na základě nějaké
mapovací tabulky[4], kde je pro každý jmenný prostor určeno odpovídající
schéma. Tím budeme mít zaručeno, že zvalidovaný dokument opravdu
odpovídá schématu, se kterým naše aplikace pro další zpracování
dokumentu počítá.
Když se spolehneme na atributy pro připojení schématu, může nám kdokoliv podvrhnout jakýkoliv dokument, pro který někde na webu vystavil svoje vlastní schéma. Takový dokument projde validací, ale naše aplikace bude mít v lepším případě problémy s jeho zpracování, v horším ji to zcela vyvede z míry.
Postupem času se vyvinulo několik přístupů k tomu, jak správně vystavět schéma. Problém, který je potřeba rozhodnout, spočívá ve výběru, kdy používat lokální, a kdy globální elementy, jak moc bude schéma rozšiřitelné a použitelné v dalších schématech.
Rozdíly mezi jednotlivýmu přístupy si ukážeme na následujícím jednoduchém dokumentu.
Příklad 3.10. Ukázkový dokument –
wxs/zamestnanec.xml
<?xml version="1.0" encoding="UTF-8"?>
<zamestnanec>
<jmeno>Jan</jmeno>
<prijmeni>Novák</prijmeni>
<adresa>
<ulice>Dlouhá 2</ulice>
<město>Praha 1</město>
<psč>110 00</psč>
</adresa>
<plat>34500</plat>
</zamestnanec>První přístup je označován jako matrjóška, tedy ruská panenka, kdy do sebe zapadají jednotlivé menší a menší panenky. V tomto přístupu je globální jen jeden element a všechny ostatní jsou uvnitř něj definovány jako lokální.
Příklad 3.11. Schéma ve stylu matrjóška –
wxs/zamestnanec-matrjoska.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="zamestnanec"> <xs:complexType> <xs:sequence> <xs:element name="jmeno" type="xs:string"/> <xs:element name="prijmeni" type="xs:string"/> <xs:element name="adresa"> <xs:complexType> <xs:sequence> <xs:element name="ulice" type="xs:string"/> <xs:element name="město" type="xs:string"/> <xs:element name="psč" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="plat" type="xs:decimal"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
Instance tohoto schématu může začínat jen elementem
zamestnanec, a jiný element ani nejde znovu
použít v jiných schématech, které by toto schéma importovaly.
Výhodou je naopak krátké a kompaktní schéma, které je rychle
napsané.
Druhý častý přístup se nazývá salámová kolečka. Všechny elementy jsou definovány jako globální a pak jsou složeny dohromady pomocí odkazů.
Příklad 3.12. Schéma ve stylu salámových koleček –
wxs/zamestnanec-salam.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="jmeno" type="xs:string"/> <xs:element name="prijmeni" type="xs:string"/> <xs:element name="ulice" type="xs:string"/> <xs:element name="město" type="xs:string"/> <xs:element name="psč" type="xs:string"/> <xs:element name="plat" type="xs:decimal"/> <xs:element name="adresa"> <xs:complexType> <xs:sequence> <xs:element ref="ulice"/> <xs:element ref="město"/> <xs:element ref="psč"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="zamestnanec"> <xs:complexType> <xs:sequence> <xs:element ref="jmeno"/> <xs:element ref="prijmeni"/> <xs:element ref="adresa"/> <xs:element ref="plat"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
Dokument může začínat libovolným elementem, libovolný element můžeme znovu použít. Nevýhoda je, že v tomto přístupu nejde pro element stejného názvu definovat dva různé modely obsahu v závislosti na kontextu jeho výskytu. Tuto možnost první způsob nabízí.
Třetí metoda, označovaná jako metoda slepého Benátčana, pro všechny elementy nejprve definuje typy, které lze znovu používat. Elementy jsou pak definovány lokálně pomocí těchto typů, takže mohou mít při shodě jmen různé modely obsahu. Tento přístup nabízí nejvíce možností a komfortu, a ve většině případů je nejvhodnější. Jeho nevýhodou je větší pracnost a složitost v porovnání s předchozími metodami.
Příklad 3.13. Schéma ve stylu slepého Benátčana –
wxs/zamestnanec-benatcan.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:simpleType name="jmenoType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="15"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="prijmeniType"> <xs:restriction base="xs:string"> <xs:minLength value="1"/> <xs:maxLength value="20"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="uliceType"> <xs:restriction base="xs:string"/> </xs:simpleType> <xs:simpleType name="městoType"> <xs:restriction base="xs:string"/> </xs:simpleType> <xs:simpleType name="psčType"> <xs:restriction base="xs:token"> <xs:pattern value="[0-9]{3} [0-9]{2}"/> </xs:restriction> </xs:simpleType> <xs:simpleType name="platType"> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0"/> </xs:restriction> </xs:simpleType> <xs:complexType name="adresaType"> <xs:sequence> <xs:element name="ulice" type="uliceType"/> <xs:element name="město" type="městoType"/> <xs:element name="psč" type="psčType"/> </xs:sequence> </xs:complexType> <xs:complexType name="zamestnanecType"> <xs:sequence> <xs:element name="jmeno" type="jmenoType"/> <xs:element name="prijmeni" type="prijmeniType"/> <xs:element name="adresa" type="adresaType"/> <xs:element name="plat" type="platType"/> </xs:sequence> </xs:complexType> <xs:element name="zamestnanec" type="zamestnanecType"/> </xs:schema>
Velkou nevýhodou XML z pohledu databázistů byla neexistence standardního mechanismu pro zaznamenání toho, že nějaký element obsahuje nedefinovanou hodnotu (NULL). Oba XML zápisy
<autor></autor> <autor/>
můžeme chápat jako element autor, který
obsahuje hodnotu prázdný řetězec. Pro zachycení hodnoty NULL můžeme
použít další globální atribut (používají se i pro připojení
schématu):
<autor xsi:nil="true"></autor> <autor xsi:nil="true"/>
To, že element může nabývat prázdnou hodnotu, musíme předtím definovat ve schématu:
w
x
s<xs:element name="autor" nillable="true" type="xs:string"/>
Konstrukci xsi:nil využívají zejména různé
nástroje pro databinding. Obvyklý přístup ve světě XML je ten, že
pokud může být nějaká hodnota nedefinovaná, tak se odpovídající
element/atribut do výstupu vůbec nevloží – ve schématu pak musí být
definován jako volitelný.
Chceme-li zabránit výskytu duplicitních hodnot v nějaké množině elementů nebo atributů, můžeme si definovat unikátní klíč. Klíčů může být v jednom schématu definováno několik a pro jejich definici se používá dotazovací jazyk XPath.
Použití klíče si ukážeme na příkladě. Předpokládejme, že
v následujícím seznamu zaměstnanců chceme zajistit unikátnost
jejich osobních čísel (atribut oc).
Příklad 3.14. Seznam zaměstnanců –
wxs/zamestnanci.xml
<?xml version="1.0" encoding="UTF-8"?> <zamestnanci> <zamestnanec oc="1164"> <jmeno>Procházka Karel</jmeno> <sef>2021</sef> </zamestnanec> <zamestnanec oc="1168"> <jmeno>Novotná Alena</jmeno> <sef>2021</sef> </zamestnanec> <zamestnanec oc="1230"> <jmeno>Klíma Josef</jmeno> <sef>1168</sef> </zamestnanec> <zamestnanec oc="1564"> <jmeno>Pinkas Josef</jmeno> <sef>2021</sef> </zamestnanec> <zamestnanec oc="2021"> <jmeno>Kládová Adéla</jmeno> </zamestnanec> </zamestnanci>
Klíč proto definujeme u elementu
zamestnanci, který obsahuje jednotlivé zaměstnance,
pro které se má dodržovat unikátnost osobního čísla.
Příklad 3.15. Definice unikátního klíče – wxs/zamestnanci-unique.xsd
w
x
s<xs:element name="zamestnanci"> <xs:complexType> <xs:sequence> <xs:element ref="zamestnanec" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> <xs:unique name="oc_je_unikatni"> <xs:selector xpath="zamestnanec"/> <xs:field xpath="@oc" /> </xs:unique> </xs:element>
Důležité je, aby definice klíče byla umístěna v definici elementu, který pod sebou jako potomky obsahuje elementy, pro které se referenční integrita hlídá. V opačném případě nebude klíč fungovat správně.
Klíč definovaný pomocí unique
kontroluje pouze unikátnost hodnot, ale neohlásí chybu, pokud
u některého elementu klíč chybí. Chceme-li mít zaručeno, že
hodnoty jsou unikátní a jsou uvedeny všude, můžeme použít element
key (viz příklad
wxs/zamestnanci-key.xsd).
Podobně jako v relační databázi, můžeme i na půdě jednoho dokumentu XML definovat referenční integritu. Postup je obdobný jako u databází – definujeme si klíče a pak cizí klíče, které na ně ukazují. Následující ukázka ilustruje omezení, které zajistí, že pro každého zaměstnance bude existovat jeho šéf.
Příklad 3.16. Definice referenční integrity – wxs/zamestnanci-keyref.xsd
w
x
s<xs:element name="zamestnanci"> <xs:complexType> <xs:sequence> <xs:element ref="zamestnanec" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> <xs:key name="osobni_cislo"> <xs:selector xpath="zamestnanec"/> <xs:field xpath="@oc"/> </xs:key> <xs:keyref name="sef_je_existujici_oc" refer="osobni_cislo"> <xs:selector xpath="zamestnanec"/> <xs:field xpath="sef"/> </xs:keyref> </xs:element>
Při návrhu schémat máme k dispozici několik vlastností, které jsou hodně podobné vlastnostem známým z objektově orientovaných jazyků. Možnost odvozování nových typů na základě již existujících není nic jiného než dědičnost. Odvozování jde přitom použít i pro komplexní typy, ne jen pro jednoduché, jak jsme si ukázali.
Komplexní typy lze odvozovat rozšířením a restrikcí. Při rozšíření jde však nové elementy přidávat pouze na konec modelu obsahu, což je velmi omezující. Při odvození nového komplexního typu restrikcí je potřeba celý nový model obsahu vypsat. Díky těmto omezením jsou tyto rysy WXS většinou nepoužívané, protože je lze nahradit jednodušeji pomocí ostatních konstrukcí. Jediné kdy se jejich použití hodí, je v případech, kdy čteme dokument pomocí PSVI a chceme mít k dispozici informaci o tom, jak jsou od sebe jednotlivé typy navzájem odvozené.
Zajímavým rysem jsou substituční skupiny. Ty umožňují definovat element, který může být v instanci nahrazen jakýmkoliv jiným elementem patřícím do stejné substituční skupiny. Výhodou tohoto přístupu je pak zejména možnost přidávat nové varianty pro nahrazení elementu v modularizovaných schématech.
Následující dokument ukazuje adresář, kde osoba může být identifikována buď přezdívkou, nebo plným jménem.
<adresář>
<osoba>
<plnéJméno>
<křestní>Jan</křestní>
<příjmení>Novák</příjmení>
</plnéJméno>
<email>jan.novak@example.org</email>
</osoba>
<osoba>
<přezdívka>Drsňák</přezdívka>
<email>jiri.prochazka@example.org</email>
</osoba>
</adresář>Tohoto efektu můžeme samozřejmě dosáhnout pomocí choice, ale substituční skupina umožní v budoucnu
snadno přidávat další varianty identifikace osoba.
Příklad 3.17. Schéma se substituční skupinou –
wxs/substituce.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="jméno" abstract="true"/> <xs:element name="přezdívka" substitutionGroup="jméno" type="xs:string"/> <xs:element name="plnéJméno" substitutionGroup="jméno"> <xs:complexType> <xs:all> <xs:element name="křestní" type="xs:string"/> <xs:element name="příjmení" type="xs:string"/> </xs:all> </xs:complexType> </xs:element> <xs:element name="osoba"> <xs:complexType> <xs:sequence> <xs:element ref="jméno"/> <xs:element name="email" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="adresář"> <xs:complexType> <xs:sequence maxOccurs="unbounded"> <xs:element ref="osoba"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
Vidíme, že element jméno, který slouží jako
začátek substituční skupiny je definován jako abstraktní, aby jej
nešlo použít přímo v instanci dokumentu.
Substituční skupiny lze využít pro psaní schémat, které umožňují
následné snadné přizpůsobení. Pomocí elementu include je možné schéma skládat dohromady
z několika souborů. V novém schématu tak můžeme načíst již existující
a přidávat nové elementy do substituční skupiny.
Příklad 3.18. Přidání elementu do substituční skupiny –
wxs/substituce-include.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:include schemaLocation="substituce.xsd"/> <xs:element name="krycíJméno" substitutionGroup="jméno" type="xs:string"/> </xs:schema>
Mezi další objektově inspirované rysy patří možnost zablokovat
další dědění nebo substituce od nějakého datového
typu. Slouží k tomu atributy final a block. První blokuje další úpravy ve schématu,
druhý v jeho instancích.
W3C XML schémata nabízejí několik prostředků, které usnadňují modularizaci schémat.
Pokud se nějaká část modelu obsahu opakuje na více místech
schématu, můžeme ji definovat pouze jednou pomocí elementu group, a pak se na ni opakovaně odkazovat pomocí
stejného elementu. Tento postup je v němčem podobný definici
komplexního datového typu. Rozdíl je v tom, že skupina elementů může
být použita kdekoliv, třeba i uvnitř sekvence elemenů.
Příklad 3.19. Opakované využití skupiny elementů – wxs/group.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:group name="adresa"> <xs:sequence> <xs:element name="ulice" type="xs:string"/> <xs:element name="město" type="xs:string"/> <xs:element name="psč" type="xs:string"/> </xs:sequence> </xs:group> <xs:element name="osoba"> <xs:complexType> <xs:sequence> <xs:element name="jméno" type="xs:string"/> <xs:group ref="adresa"/> <xs:element name="zaměstnání"> <xs:complexType> <xs:sequence> <xs:element name="firma" type="xs:string"/> <xs:group ref="adresa"/> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
Podobně jako skupiny elementů fungují i skupiny atributů. Pro
jejich definici se však používá element attributeGroup.
Příklad 3.20. Opakované využití skupiny atributů –
wxs/attributegroup.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:attributeGroup name="společnéAtributy"> <xs:attribute name="id" type="xs:ID"/> <xs:attribute name="lang" type="xs:language"/> </xs:attributeGroup> <xs:element name="doc"> <xs:complexType> <xs:sequence> <xs:element name="title"> <xs:complexType> <xs:simpleContent> <xs:extension base="xs:string"> <xs:attributeGroup ref="společnéAtributy"/> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> <xs:element name="p"> <xs:complexType> <xs:simpleContent> <xs:extension base="xs:string"> <xs:attributeGroup ref="společnéAtributy"/> </xs:extension> </xs:simpleContent> </xs:complexType> </xs:element> </xs:sequence> <xs:attributeGroup ref="společnéAtributy"/> </xs:complexType> </xs:element> </xs:schema>
Máme-li jednou velké schéma a chceme jej rozdělit do více
menších souborů pro lepší přehlednost, můžeme výsledné schéma složit
z několika částí pomocí elementu include.
<xs:include schemaLocation="cast-schematu.xsd"/>
Element include má ještě jedno
speciální využití. Pokud načítané schéma nemá určen cílový jmenný
prostor, převezmou načítané deklalarace cílový jmenný prostor
schématu, které obsahuje include. Tomuto
přístupu se přezdívá „chameleon design“ a nelze jej obecně
doporučit.
Někdy se nám může hodit načtení existujícího schématu a jeho
následné drobné úpravy. K tomu slouží element redefine. Chová se podobně jako include, ale umožňuje změnit libovolné načítané
definice jednoduchého a komplexního datového typu a skupiny elementů
a atributů. Jsou přitom dovoleny jen změny, které vyhovují podmínkám
pro odvozování pomocí restrikce nebo extenze. Nově přidávané elementy
se tedy mohou objevit pouze na konci modelu obsahu a zúžené modely
obsahy musí být podmnožinou těch původních.
Následující příklad využití redefine ukazuje přidání nového elementu do již
existujícího komplexního typu. Pro tento způsob rozšiřování schémat je
vhodné používat při návrhu „slepého Benátčana“, kdy je
pro vše k dispozici datový typ, který lze dále upravovat.
Příklad 3.21. Ukázka přidání podelementu redefinicí –
wxs/redefine-pridani.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:redefine schemaLocation="zamestnanec-benatcan.xsd"> <xs:complexType name="adresaType"> <xs:complexContent> <xs:extension base="adresaType"> <xs:sequence> <xs:element name="stát" type="xs:string"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> </xs:redefine> </xs:schema>
Pokud by schéma bylo navrženo s využitím skupin elementů, bylo
by možné nový element přidat i na jiné místo, než na samotný konec
elementu adresa.
Příklad 3.22. Ukázka přidání podelementu redefinicí skupiny elementů –
wxs/redefine-pridani-group.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:redefine schemaLocation="zamestnanec-benatcan-group.xsd"> <xs:group name="adresaGroup"> <xs:sequence> <xs:element name="stát" type="xs:string"/> <xs:group ref="adresaGroup"/> </xs:sequence> </xs:group> </xs:redefine> </xs:schema>
Na závěr tu máme ještě ukázku využití redefine ve spojení se složitějším schématem. Ve
schématu pro XHTML upravíme definici elementu tr
tak, aby dovoloval jen podelement td.
Příklad 3.23. Ukázka redefinice –
wxs/redefine.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.w3.org/1999/xhtml" xmlns="http://www.w3.org/1999/xhtml"> <xs:redefine schemaLocation="xhtml11/xhtml11.xsd"> <xs:group name="tr.content"> <xs:sequence> <xs:choice maxOccurs="unbounded"> <!-- Odstraníme element th: <xs:element ref="th"/> --> <xs:element ref="td"/> </xs:choice> </xs:sequence> </xs:group> </xs:redefine> </xs:schema>
Varování
Výše uvedený příklad nepůjde v některých validátorech
zpracovat. Je to způsobeno tím, že předefinovávaná skupina není přímo
v načítaném schématu (xhtml11/xhtml11.xsd), ale
je do něj načtena pomocí include. Ze
specifikace není zcela zřejmé, jak se má v tomto případě
postupovat. Konstrukci redefine je proto
bezpečnější používat pouze v případě, že redefinovaná skupina je ve
schématu obsažena přímo.
Nejasnosti v používání redefine
došly tak daleko, že nová verze schémat 1.1 nedoporučuje tuto
konstrukci používat.
Chceme-li definovat schéma dokumentu, který se skládá
z elementů v různých jmenných prostorech, využijeme naopak
elementu import. Ten umožňuje do
schématu načíst definice elementů a typů patřících do jiného jmenného
prostoru. Následující příklad ukazuje import schématu jazyka XHTML do
našeho schématu.
Příklad 3.24. Schéma importují schéma pro XHTML –
wxs/message.xsd
w
x
s<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs='http://www.w3.org/2001/XMLSchema' xmlns:html="http://www.w3.org/1999/xhtml"> <xs:import namespace="http://www.w3.org/1999/xhtml" schemaLocation="xhtml11/xhtml11.xsd"/> <xs:element name="message"> <xs:complexType> <xs:sequence> <xs:element name="from" type="xs:string"/> <xs:element name="to" type="xs:string"/> <xs:element name="subject" type="xs:string"/> <xs:choice> <xs:element name="body" type="xs:string"/> <xs:element ref="html:body"/> </xs:choice> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
Příklad 3.25. Zpráva s textovým tělem –
wxs/zprava1.xml
<?xml version="1.0" encoding="UTF-8"?> <message xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="message.xsd"> <from>adam@example.org</from> <to>eva@example.org</to> <subject>Pokusný email v textu</subject> <body>Tělo e-mailu.</body> </message>
Příklad 3.26. Zpráva s XHTML tělem –
wxs/zprava2.xml
<?xml version="1.0" encoding="UTF-8"?> <message xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="message.xsd"> <from>adam@example.org</from> <to>eva@example.org</to> <subject>Pokusný email v textu</subject> <body xmlns="http://www.w3.org/1999/xhtml"> <h1>E-mail zapsaný v HTML</h1> <p>První odstavec.</p> <p>Druhý odstavec</p> <table> <tr><th>A</th><th>B</th></tr> <tr><td>2</td><td>7</td></tr> </table> </body> </message>
Tuto metodu musíme využít vždy, kdy chceme definovat schéma
s elementy v několika jmenných prostorech, protože v jednom schématu
lze definovat pouze elementy patřící do cílového jmenného prostoru
určeného atributem targetNamespace.
Při kombinování elementů z několika jmenných prostorů si však můžeme vybrat, jak těsně jednotlivá schémata svážeme dohromady. Předchozí příklad zcela explicitně vyjadřoval, kde se může nějaký element vyskytovat. Je možný však i volnější přístup. Předpokládejme například, že chceme validovat zprávy SOAP, které přenášejí námi definovaná data.
Příklad 3.27. SOAP zpráva – wxs/soap-zprava.xml
<?xml version="1.0" encoding="UTF-8"?> <Envelope xmlns="http://www.w3.org/2003/05/soap-envelope" xmlns:p="urn:x-pokus:ws-payload"> <Header> <p:UserId>Pepa</p:UserId> </Header> <Body> <p:GetFoo> <p:foo>abc</p:foo> <p:bar>def</p:bar> </p:GetFoo> </Body> </Envelope>
Elementy Envelope, Header
a Body jsou přitom definovány ve standardně
dostupném schématu pro SOAP
(wxs/soap.xsd). Protože však uvnitř zprávy SOAP
mohou být libovolná uživatelská data, nemůže schéma SOAP předdefinovat
konkrétní obsah pro elementy Header
a Body. Místo toho se zde používá konstrukce
any, která umí validovat jakýkoliv
element.
<xs:any namespace="##any" processContents="lax" minOccurs="0" maxOccurs="unbounded"/>
V tomto případě parametry any
určují, že zastupuje element z libovolného jmenného prostoru
(namespace="##any") a že tento element se může
validovat vůči dalšímu schématu, je-li takové schéma k dispozici
(processContents="lax").
Aby byla validace důkladná, musíme si vytvořit schéma pro naše elementy uvnitř zprávy SOAP.
Příklad 3.28. Schéma pro obsah zprávy SOAP – wxs/payload.xsd
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="urn:x-pokus:ws-payload" elementFormDefault="qualified"> <xs:element name="GetFoo"> <xs:complexType> <xs:sequence> <xs:element name="foo" type="xs:string"/> <xs:element name="bar" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="UserId" type="xs:string"/> </xs:schema>
Nyní je potřeba validátoru sdělit, kde má najít schémata pro
validaci. Jednou z možností je využití atributu schemaLocation.
<?xml version="1.0" encoding="UTF-8"?> <Envelope xmlns="http://www.w3.org/2003/05/soap-envelope" xmlns:p="urn:x-pokus:ws-payload" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instamce" xsi:schemaLocation="http://www.w3.org/2003/05/soap-envelope soap.xsd urn:x-pokus:ws-payload payload.xsd"> … </Envelope>
Při větším počtu schémat je však zadávání všech dvojic jmenný prostor
a schéma do atributu schemaLocation poměrně nepraktické. Můžeme
si proto pomoci tím, že vytvoříme jedno schéma, které naimportuje
všechna potřebná schémata.
Příklad 3.29. Složení schémat – wxs/soap-zprava.xsd
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:import namespace="http://www.w3.org/2003/05/soap-envelope" schemaLocation="soap.xsd"/> <xs:import namespace="urn:x-pokus:ws-payload" schemaLocation="payload.xsd"/> </xs:schema>
Nyní stačí pro validaci použít toto jedno schéma.
Kombinování takto volně svázaných schémat lze ovlivnit
pomocí parametrů u any. Atribut
processContents
určuje, jak se mají elementy popsané pomocí any,
validovat. Hodnota skip říká, že se takové elementy
nebudou vůbec validovat, hodnota strict říká, že se
musí validovat a konečně hodnota lax říká, že se
validace provede pouze v případě, že se pro elementy najde
odpovídající schéma.
Atribut namespace pak určuje v jakém jmenném
prostoru elementy mohou být. Jmenný prostor jde zadat buď jeden
konkrétní, kromě toho lze použít několik speciálních hodnot.
##anyzastupuje libovolný jmenný prostor
##targetNamespacezastupuje cílový jmenný prostor schématu
##otherzastupuje jakýkoliv jmenný prostor s výjimkou cílového jmenného prostoru
##localelementy nebudou v žádném jmenném prostoru
Při psaní schémat můžeme poměrně snadno narazit na několik omezení. Některé konstrukce jsou ve schématech zakázané. Někdy to má dobrý důvod, někdy lze jen o umělý relikt, protože v době práce na specifikaci nebyl široce znám efektivní algoritmus pro validaci určitých konstrukcí.
Unique Particle Attribution (UPA) je postrach každého návrháře schémat. Toto pravidlo říká, že schéma musí být vždy zcela jednoznačné, musí být vždy zcela zřejmé a jednoznačné vůči jaké části schématu se daná část dokumentu XML validuje a musí to být jasné, aniž by se ve validovaném dokumentu XML četly elementy „dopředu“.
Například následující typ pravidlo UPA poručuje, protože obě větve
schématu obsažené v kompozitoru xs:choice začínají elementem a
– pokud se však ve validovaném dokumentu takový element vyskytne, není
jasné jakou větví validace se vydat aniž bychom znali elementy, které
za a pokračují.
w
x
s<xs:complexType name="typ1"> <xs:choice> <xs:sequence> <xs:element name="a"/> <xs:element name="b"/> </xs:sequence> <xs:sequence> <xs:element name="a"/> <xs:element name="c"/> </xs:sequence> </xs:choice> </xs:complexType>
V tomto případě je řešení jednoduché – element
a můžeme vytknout před výběr mezi elementy
b a c. Tento postup však není
možné použít vždy.
w
x
s<xs:complexType name="typ2"> <xs:sequence> <xs:element name="a"/> <xs:choice> <xs:element name="b"/> <xs:element name="c"/> </xs:choice> </xs:sequence> </xs:complexType>
Pokud je v modelu obsahu na jedné úrovni několikrát deklaraván element stejného jména, musí mít vždy stejný typ. Následující definice typu je tak špatná.
w
x
s<xs:complexType name="typ3"> <xs:sequence> <xs:element name="a" type="xs:string"/> <xs:element name="a" type="xs:integer"/> </xs:sequence> </xs:complexType>
XML schéma umožňuje k libovolné jeho části připojit dokumentaci. Ta může obsahovat buď prostý text, nebo můžeme použít v odpovídajícím jmenném prostoru nějaký speciální značkovací jazyk jako XHTML nebo DocBook.
w
x
s<xs:element name="zamestnanec"> <xs:annotation> <xs:documentation>Element slouží pro uchování důležitých údajů o zaměstnanci.</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element name="jmeno" type="xs:string"/> <xs:element name="prijmeni" type="xs:string"/> <xs:element name="plat" type="xs:decimal"/> <xs:element name="narozen" type="xs:date"/> </xs:sequence> </xs:complexType> </xs:element>
w
x
s<xs:simpleType name="DruhDokumentuType"> <xs:annotation> <xs:documentation xmlns="http://www.w3.org/1999/xhtml"> <p>Druh účetního dokumentu.</p> <p>Podporovány jsou následující hodnoty:</p> <table> <tr> <td>1</td> <td>faktura</td> </tr> <tr> <td>2</td> <td>dobropis</td> </tr> <tr> <td>3</td> <td>vrubopis</td> </tr> </table> <p>Více podrobností <a href="http://example.com/ciselnik">v číselníku MF</a>.</p> </xs:documentation> </xs:annotation> <xs:restriction base="xs:integer"> <xs:enumeration value="1"/> <xs:enumeration value="2"/> <xs:enumeration value="3"/> </xs:restriction> </xs:simpleType>
Existují nástroje, které jsou pak schopné na základě schématu a v něm obsažených komentářů vygenerovat přehlednou dokumentaci. Jedním z těchto nástrojů je xs3p dostupné na adrese http://sourceforge.net/projects/xs3p/. Jedná se o XSLT styl, který umí schéma převést do webové stránky.
Vygenerování dokumentace tak spočívá v prostém aplikování XSLT stylu na schéma:
saxon -o faktura.html faktura.xsd ../tools/xs3p.xslAnalogickou a většinou ještě komfortnější funcionalitu mívají přímo do sebe zabudované i editory XML a schémat.
Podobným způsobem lze do elementu appInfo přidat i různé aplikačně závislé
informace. Třeba doplňkovou validaci pomocí Schematronu.
Na jaře 2012 byla vydána nová verze XML Schema 1.1, která se snaží odstranit některá omezení a nedostatky předchozích verzí. Bohužel praktické nasazení bude pomalé. V současné době novou verzi podporují pouze dva validátory Saxon-EE a Xerces-J. Kromě uzavřených scénářů tak není vhodné schémata ve verzi 1.1 vytvářet, protože většina nástrojů je nebude schopna použít. I přesto se však alespoň stručně podíváme na některé nejdůležitější novinky.
Některá víceméně umělá omezení byla odstraněna, např.:
UPA omezení se nyní nevztahují na nejednoznačnost mezi elementem a
xs:any;psát rozšiřitelná schémata je nyní jednoduší, protože lze vytvářet otevřené modely obsahu, kde není nutné explicitně uvádět
xs:any;uvnitř
xs:alllze používat větší počet opakování než jedna.
V praxi se poměrně často setkáme se situacemi, kdy model obsahu
se liší na základě hodnoty uvedené v nějakém atributu. XML schémata to
uměla řešit jen velmi nešikovně pomocí
xsi:type. V nové verzi to lze elegantněji vyřešit
podmíněným přiřazením typu na základě výsledku výrazu XPath.
w
x
s<xs:element name="adresa" type="adresaType"> <xs:alternative test="@stat='usa'" type="americkaAdresaType"/> <xs:alternative test="@stat='eu'" type="evropskaAdresaType"/> <xs:alternative type="xs:error"/> </xs:element>
V našem příkladě by přitom oba dva typy
americkaAdresaType a
evropskaAdresaType musely být odvozeny od typu
adresaType.
XML Schema 1.1 přidává podporu pro nové datové typy
xs:dayTimeDuration a
xs:yearMonthDuration, které jsou používány v XQuery
a v XSLT 2.0.
Nově je také dovoleno, aby jednotlivé implementace nabízely své vlastní primitivní datové typy nad rámec standardu.
Jedná se o asi nejužitečnější rozšíření, které je inspirováno Schematronem. Každý typ může mít k sobě připojené podmínky zapsané v jazyce XPath 2.0. Ty se nevyhodnocují proti celému dokumentu, ale jen vůči podstromu odpovídajícímu datovému typu. Pokud některá z podmínek vrátí chybu nebo false, dokument není považován za validní.
w
x
s<xs:element name="faktura"> <xs:complexType> <xs:sequence> … </xs:sequence> <xs:attribute name="vystaveni" type="xs:date" use="required"/> <xs:attribute name="splatnost" type="xs:date" use="required"/> <xs:assert test="@splatnost ge @vystaveni"/> </xs:complexType> </xs:element>
Podstatnou nevýhodou oproti Schematronu je nemožnost definice vlastního chybového hlášení.
[2] Příslušnost znaku do třídy jde zjistit v unicodové databázi – http://www.unicode.org/Public/UNIDATA/UnicodeData.txt. K dispozici je i přehled bloků – http://www.unicode.org/Public/UNIDATA/Blocks.txt.
[3] Skutečnost je taková, že all může být použito
jen přímo uvnitř komplexního typu a nemůže být kombinováno
s dalšími konstrukcemi jako sequence a
choice.