 |
Soudě podle ohlasu mnohých z vás, čtenářů našeho seriálu, se dnes dostaneme k tématu, které vás velmi zajímá. Je to celkem pochopitelné. Pryč jsou doby, kdy pro kvalitní prezentaci firmy na Webu stačilo pár statických stránek provázaných odkazy. Díky silné konkurenci je dnes nezbytné podbízet se zákazníkům dalšími užitečnými službami. Na firemním Webu by tedy neměl chybět ceník produktů s možností vyhledávání, stránka sloužící k objednání výrobků apod. Mnohé firmy jdou ještě dál a na webových technologiích mají postaveny celé své informační systémy. Všechny zmíněné aplikace pracují s velkým množstvím dat, která se obvykle ukládají do databází. V následujících dílech seriálu se proto budeme podrobně zabývat tím, jak zpřístupnit databáze pomocí Webu. Kromě popisu obecných principů a postupů si ukážeme praktickou práci s databázemi v prostředích PHP a ASP.
Stojím teď před nelehkým úkolem vysvětlit na omezeném prostoru našeho seriálu mnoho důležitých pojmů z oblasti zpracování dat. Přitom toto téma by samo o sobě vydalo na nejednu tlustou knihu. Seznámíme se tedy pouze s tím, co je pro nás nezbytné. Zájemce o detailnější a ucelenější informace odkáži na odbornou literaturu a na seriál kolegy Pokorného, který vychází na stránkách Computerworldu již několik let.
Databázi si můžeme představit jako místo, kam se ukládají všechny potřebné údaje. Přístup k údajům uloženým v databázi obstarává program, kterému se říká SŘBD -- Systém Řízení Báze Dat. Tento poněkud krkolomný název vznikl přeložením původního anglického termínu DBMS -- DataBase Management System. Mezi SŘBD patří takové programy jako Oracle, MS SQL Server, Sybase, Informix, Progress. Nejedná se o programy nikterak levné. Jejich cena se pohybuje v desítkách a většinou spíše i ve stovkách tisíc korun. Naštěstí i na poli SŘBD existují programy šířené zdarma jako freeware -- např. mSQL, MySQL a PostgreSQL.
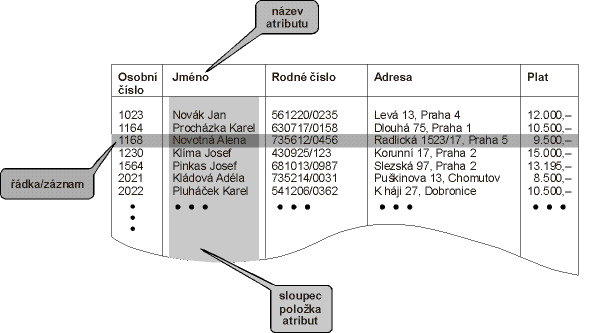
Převážná většina dnes používaných SŘBD při uspořádání údajů v databázi vychází z relačního modelu dat. Název tohoto modelu vychází z relační algebry, což je matematický aparát, na kterém relační model dat staví. V tomto modelu jsou údaje uspořádány do tabulek. Tabulka zpravidla shromažďuje údaje o jednom druhu objektů. Můžeme tak mít například tabulku s osobními údaji zaměstnanců. Jednotlivé řádky odpovídají jednotlivým zaměstnancům. Sloupce pak obsahují informace o pracovnících -- v našem případě by to mohly být následující údaje: osobní číslo, jméno, rodné číslo, adresa a výše platu. Sloupcům tabulky obvykle říkáme v databázové terminologii položky nebo atributy. Jednotlivé řádky se pak nazývají záznamy. Vše se nám pokusí přiblížit obrázek 1.
|
Aby šlo s tabulkami a v nich uloženými údaji pracovat, musí být nějak
jednoznačně identifikovány. Každý sloupec je proto pojmenován -- má svůj
název. Tento název pak používáme, když se odvoláváme na obsah určitého
atributu a ne na celý záznam. Jménem atributu jsou v naší tabulce např.
Jméno a Plat.
Častou operací prováděnou v tabulkách je změna obsahu jednoho
atributu u určitého záznamu. Pro provedení této operace však musíme mít
k dispozici způsob, jak jednoznačně určit požadovaný záznam. Pro tyto
účely by každá tabulka měla obsahovat tzv. primární klíč.
Primární klíč je atribut, jehož hodnota je pro každý záznam jedinečná. V
našem případě tedy jako primární klíč může posloužit atribut
Osobní číslo, protože každý zaměstnanec má své vlastní
osobní číslo. Našim požadavkům na primární klíč vyhoví i rodné číslo --
to má každý občan České republiky jedinečné.
Chybou by však bylo za primární klíč zvolit např. atribut
Jméno. Na první pohled se jména zaměstnanců liší. Není však
problém, aby se ve větší firmě vyskytli dva Janové Nováci. Pak bychom
je podle jména rozlišili velice těžko.
Pro každý atribut tabulky musíme určit jaký typ dat může obsahovat. Mezi nejběžněji používané typy patří celá čísla, znakové řetězce a logické hodnoty (ano/ne). Další velmi často používané typy jsou reálná čísla, měnové údaje, datum a čas. Mnoho SŘBD podporuje i složitější typy jako je obrázek, video či audio klip.
Databáze může samozřejmě obsahovat větší množství tabulek -- záleží
na tom, co vše za údaje chceme do databáze zaznamenat. Každá tabulka má
proto své jméno, které ji v rámci databáze jednoznačně identifikuje. V
našem případě by tabulka měla nejspíše název Zaměstnanci.
Někdy se používá pouze jednotné číslo, potom by naše tabulka měla jméno
Zaměstnanec. Jméno tabulky by vždy mělo odpovídat jejímu
obsahu, usnadníme si tak pozdější orientaci ve větším množství tabulek.
Vidíme, že tabulka obvykle obsahuje ucelené informace. To však
neznamená, že nijak nesouvisí s ostatními tabulkami. Představme si, že v
naší fiktivní firmě chceme evidovat informace o odběratelích. U každého
odběratele budeme chtít evidovat jeho IČO, název, sídlo a našeho
zaměstnance, který má styk s odběratelem na starosti. Je jasné, že
tabulka Odběratelé musí obsahovat atributy IČO, název a
sídlo. Má však u každého odběratele obsahovat kompletní informace o
zaměstnanci (tj. jeho jméno, rodné číslo, rodné číslo, adresu a výši
platu . To by jistě nebylo nejefektivnější -- pokud by někdo měl na
starosti více odběratelů, informace by se v tabulce zbytečně opakovaly.
Výše zmíněné případy se řeší pomocí vztahů mezi tabulkami. V
našem případě může mít jeden zaměstnanec na starosti několik odběratelů
a hovoříme tedy o vztahu 1:N. V praxi se tento vztah řeší tak, že
tabulka Odběratelé má atribut, který obsahuje primární klíč
určující zaměstnance pověřeného stykem s firmou. Primární klíč v tabulce
zaměstnanci je osobní číslo, u každého odběratele tedy uvedeme osobní
číslo zaměstnance pověřeného jednat za naši firmu (viz obr. 2).
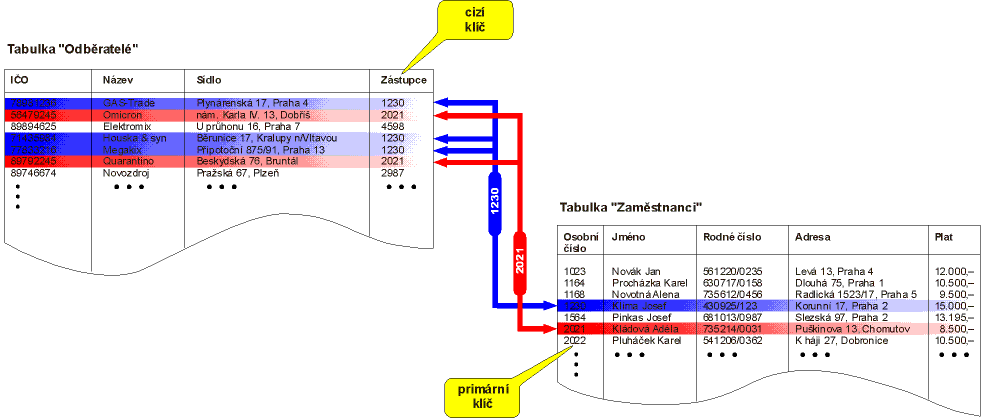 |
Vidíme, že použité uspořádání údajů do tabulek nám dává k dispozici
všechny informace. Pokud chceme zjistit, kdo má na starosti firmu
Omicron, podíváme se do tabulky Odběratelé. V ní zjistíme,
že se jedná o zaměstnance s osobním číslem 2021. Podíváme
se do tabulky zaměstnanci a zjistíme, že osobní číslo 2021
má Adéla Kládová.
Můžeme postupovat i opačně. Pokud nás zajímá, kteří odběratelé
spadají do péče Josefa Klímy, zjistíme jeho osobní číslo --
1230. Příslušní odběratelé v tabulce
Odběratelé mají toto číslo uloženo v atributu
Zástupce.
Atributu, který slouží jako odkaz na jinou tabulku a obsahuje tedy primární klíče jiné tabulky, říkáme cizí klíč. Pokud se tabulka účastní více vztahů s ostatními tabulkami může obsahovat více cizích klíčů. Primární klíč je však v každé tabulce vždy jen jeden.
Mezi tabulkami mohou existovat i jiné vztahy než 1:N, i když nejsou tak časté. Vztah 1:1 vyjadřuje případy, kdy záznam jedné tabulky odpovídá jednomu záznamu jiné tabulky. Tyto vztahy se obvykle řeší jako speciální případ vztahu 1:N s využitím cizího klíče.
Jisté komplikace přináší vztahy typu M:N. Jak takový vztah vypadá?
Představme si, že naše fiktivní firma zpracovává najednou několik
projektů. Na každém projektu může pracovat několik zaměstnanců, ale
zároveň může jeden zaměstnanec pracovat na více projektech. Vztah mezi
tabulkami Projekty a Zaměstnanci je právě
vztahem M:N.
Na první pohled se vztah M:N nedá do relačního modelu dat napasovat. Naštěstí lze každý vztah M:N rozložit na dva vztahy 1:N s využitím pomocné tabulky. Ukažme si vše na našem příkladě.
Informace o projektech budeme ukládat do tabulky
Projekty. Předpokládejme, že každý projekt je identifikován
svým ID-číslem, které zvolíme jako primární klíč tabulky. Vztahy mezi
projekty a zaměstnanci zachytíme v tabulce Proj-Zam. Každý
záznam této tabulky obsahuje ID projektu a číslo zaměstnance, který na
něm pracuje. Pokud na nějakém projektu pracuje více zaměstnanců, bude v
tabulce několik záznamů se stejným ID projektu a rozdílným číslem
zaměstnance. Zcela obdobně to bude platit pro zaměstnance. Pokud jeden
zaměstnanec pracuje na více projektech, bude v tabulce několik řádků se
stejným osobním číslem zaměstnance a různým ID projektu (viz obr. 3).
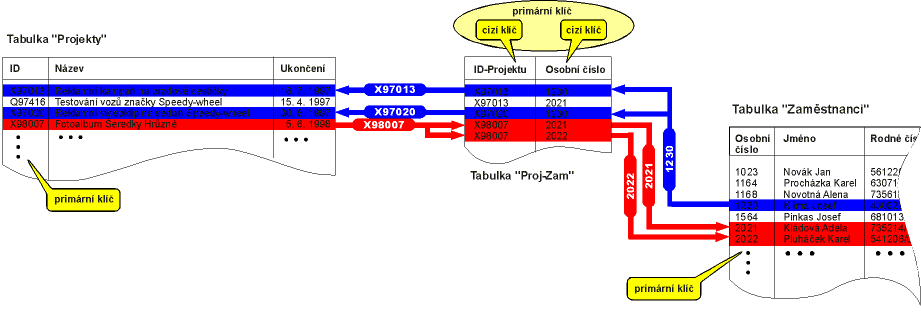 |
Pomocí tabulky Proj-Zam snadno zjistíme, že Josef Klíma
pracuje na projektech X97013 a X97020. Stejně snadné je i zjištění, že
na projektu X98007 pracují Kládová a Pluháček.
Mezi tabulkami Projekty a Proj-Zam je vztah
1:N. Stejný vztah je i mezi tabulkami Zaměstnanci a
Proj-Zam. Vidíme tedy, že původního vztahu M:N jsme se
celkem jednoduše zbavili. Nově vzniklé tabulka Proj-Zam
obsahuje pouze cizí klíče z tabulek Projekty a
Zaměstnanci. Primární klíč tabulky je tvořen dohromady
oběma cizími klíči.
Z této ukázky je vidět, že primární klíč nemusí být tvořen pouze jedním atributem, ale i několika dohromady. Pro každý záznam však stále platí, že jeho primární klíč je jedinečný. Každý záznam tedy musí obsahovat jedinečnou kombinaci hodnot atributů, které jsou součástí primárního klíče.
V příštím díle si povíme, jakým způsobem může naše aplikace pomocí SŘBD pracovat s tabulkami v databázi. Z převážné většiny si proto budeme povídat o jazyce SQL. Pokud je pro vás zkratka SQL magickým zaklínadlem, určitě si počkejte na další díl seriálu a dozvíte se, o co jde.