Cílů projektu RAINBOW je několik. Lze je rozdělit do tří skupin:
Vytvoření navigačního rozhraní pro snazší pohyb po souvisejících stránkách.
Další rozšíření systému VŠEvěd [1]. Systém VŠEvěd pracuje jako nadstavba nad vyhledávacími službami. Výsledky vyhledávání umí inteligentně seskupovat a kategorizovat. Uživatel tak dostane užitečnější výsledek.
Systém pro audit stránek, který by hledal chyby na stránkách a upozorňoval na ně.
V současné době se pracuje především na první části projektu, jejímž cílem je usnadnění a zlepšení navigace na webových stránkách. Z uživatelského pohledu je cílem vyvinout rozšířený prohlížeč webových stránek, který bude ve speciálním panelu zobrazovat přídavné informace vztahující se k aktuálně zobrazované stránce. Na rozdíl od panelu What's Related by měl systém nabízet větší množství informací o aktuálně zobrazené stránce (viz obrázek 2.4).
Ve finální podobě by navigační asistent RAINBOW mohl ke každé stránce automaticky nabízet následující údaje:
Sekci metainformací o dokumentu obsahující důležité informace o aktuálním dokumentu. Přitom by se systém nemusel soustřeďovat jen na klasické metainformace jako autor, název, datum vzniku, klíčová slova, ale i na méně obvyklé – např. to, že jde o akademickou stránku, o obsah vícestránkového dokumentu apod.
Sekci podobných stránek, která bude pro většinu uživatelů zřejmě nejdůležitější, protože umožní rychlý přechod na stránky podobné podle různých kritérií – systém nabídne stránky shodné obsahově, stránky od stejného autora, nebo například stránky se stejnou formální strukturou. Uživatel by se tak mohl snadno pohybovat v prostoru pro něj zajímavých dokumentů bez nutnosti ruční práce s nějakou vyhledávací službou.
Sekci asociovaných stránek odkazující na stránky, které s tou aktuální jistým způsobem souvisejí (a nejde přitom o symetrickou podobnost). Patří sem například odkazy na předchozí a následující stránku v rámci dokumentu složeného z více fyzických stránek, na hlavní stránku, na stránku s hledáním apod. To umožňuje snadný pohyb i po špatně navržených stránkách, které neobsahují vlastní navigační prvky.
Sekci doménově závislých informací obsahující v kondenzované podobě jak metainformace, tak asociace, ovšem takové, které jsou specifické pro jistou problémovou oblast a jako takové popsané specializovanou ontologií. V rámci webového místa univerzity může jít například o identifikaci stránky kurzu, vyučujícího a katedry a jejich vzájemné odkazování. V rámci firemního webu firmy pak např. o hlavní stránku, stránku s referencemi na klienty a stránky produktů.
Má-li být navigační rozhraní opravdu ergonomické, mělo by nabízet možnost personalizace – individuálního nastavení podle potřeb uživatele. Uživatel by měl mít možnost vybrat si, jaké typy informací mu má systém nabízet.
Výše popsané úlohy nelze většinou realizovat v reálném čase tak, aby měl celý systém dostatečně rychlou odezvu. RAINBOW proto pracuje podobným způsobem jako klasické internetové vyhledávače. Předem se vždy zpracuje určitá část webu – například stránky jedné univerzity, firmy, státu, nebo třeba průmyslového odvětví. Stránky se stáhnou, provede se jejich analýza a získané informace se uloží do faktuální znalostní báze. Z této báze znalostí se pak získávají potřebné údaje pro navigační rozhraní. Při analyzování stránek některými moduly mohou být extrahovány i informace důležité pro audit stránek – například syntaktické chyby, chybějící metadata – a odeslány autorovi stránky (pokud se ze stránky podaří získat jeho e-mailovou adresu).
Vlastní analýzou obsahu a struktury stránek a příslušnými analytickými moduly se v této práci nezabývám. Jde o velmi náročnou záležitost, která vyžaduje zapojení technik umělé inteligence, znalostního inženýrství apod. V rámci projektu RAINBOW se počítá s vývojem následujících modulů:
extrakce informací z textu;
analýza metadat explicitně přítomných ve webových dokumentech;
analýza URL adres;
analýza struktury značek;
frekvenční analýza termínů;
analýza topologie odkazů;
analýza obrazových informací.
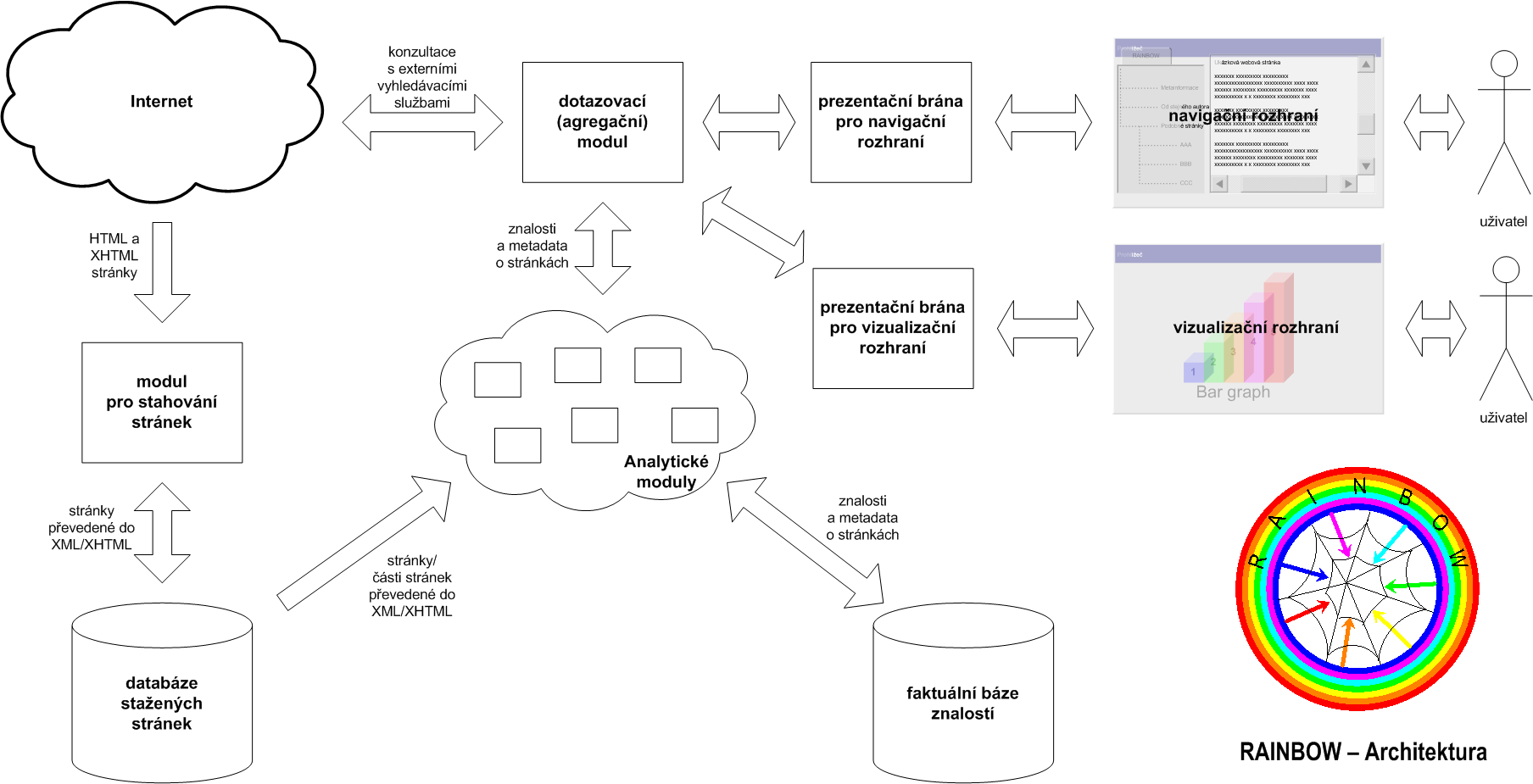
Přehledové schéma celého systému je zachyceno na obrázku 2.5. Modul pro stahování stránek se stará o stažení stránek z vybrané části Internetu. Jelikož mnoho současných webových stránek obsahuje syntaktické chyby, které by ztížily práci dalším analytickým modulům, jsou tyto chyby odstraněny, stránky převedeny do XML a následně uloženy do databáze stažených stránek.
Z této databáze se stránky předají analytickým modulům, které se v nich pokusí nalézt metadata, různé souvislosti a další zajímavé údaje. Tyto údaje se pak uloží do faktuální báze znalostí.
Bude-li chtít uživatel pracovat se systémem, musí mít nainstalován speciální prohlížeč, který pro právě prohlíženou stránku kontaktuje dotazovací modul. Ten zjistí od ostatních modulů a z faktuální báze informace o aktuální stránce a předá je zpět navigačnímu rozhraní. Podle povahy údajů může dotazovací modul některé informace získat „on-line“ od určitých analytických modulů, případně od externích služeb dostupných mimo RAINBOW. Tyto výsledky se zkombinují se složitěji získanými informacemi, které jsou uloženy „off-line“ v již zmíněné faktuální bázi znalostí.
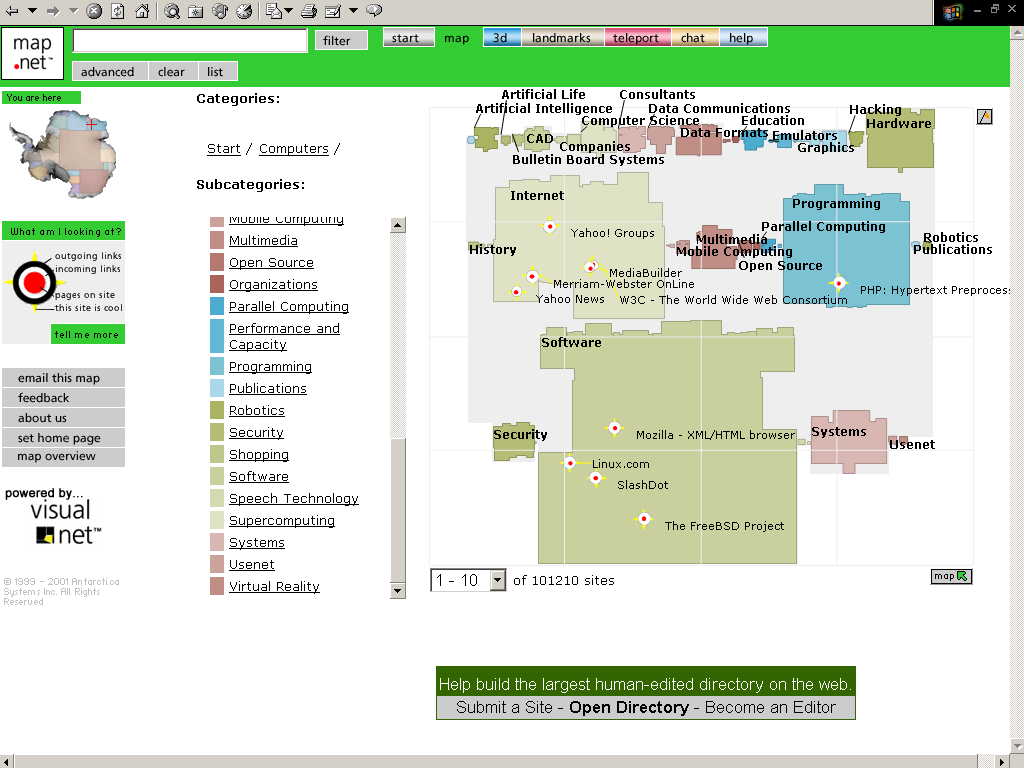
Dotazovací modul přitom nekomunikuje přímo s uživatelem, resp. rozhraním, které uživatel používá. Mezi uživatele a dotazovací modul je vložena ještě jedna vrstva, která umožňuje převedení získaných informací o stránce do různých podob. Kromě dříve popsaného navigačního rozhraní tak může později vzniknout i další rozhraní, které bude výsledky prezentovat odlišnou formou – např. vizuálně. Inspirovat se v tomto případě můžeme například systémem Visual.net firmy Antarcti.ca, který umožňuje prostorovou vizualizaci informačního prostoru (a tedy i Internetu).
Obrázek 2.6. Antarcti.ca – katalog stránek prezentovaný jako shluky v 2D prostoru
Cílem mé diplomové práce je vytvoření modulu pro stahování stránek, navigačního rozhraní, navržení a otestování vhodné komunikační infrastruktury pro moduly.