Obsah
V této části se podíváme na jednoduchý dokument v DocBooku a ukážeme si, jak ho převést do dalších formátů.
Pro zápis dokumentů v DocBooku se používá jazyk XML. Stručně si zde proto zopakuje základy syntaxe tohoto jazyka.
Každý XML dokument se skládá z elementů, které jsou do sebe navzájem vnořené. Elementy se v textu vyznačují pomocí tzv. tagů. Většině elementů odpovídají dva tagy – počáteční a koncový.
<para>Toto je obsah elementu para.</para>
Ukázka obsahuje jeden element para. Jeho obsah je vyznačen pomocí tagů
<para> (počáteční tag) a </para> (koncový tag). Jen na okraj
poznamenejme, že výše uvedená ukázka je asi nejjednodušším XML
dokumentem, který můžeme vytvořit.
Názvy tagů se zapisují mezi znaky `<' a
`>'. Koncový tag má před svým názvem ještě
znak `/', aby se snadno odlišil od
počátečního.
Některé elementy nemusejí mít žádný obsah. Můžeme je samozřejmě zapisovat tak, že za počátečním tagem uvedeme hned ten koncový.
<para>Toto je obsah elementu para.<br></br> A tohle taky.</para>
Není to však příliš pohodlné, a proto můžeme v XML
použít ještě jednu variantu tagu, která říká, že element nemá žádný
obsah. Za jméno elementu v počátečním tagu se uvede znak
`/'. Koncový tag se pak už nepoužije.
<para>Toto je obsah elementu para.<br/> A tohle taky.</para>
Každý XML dokument musí obsahovat pro všechny počáteční tagy odpovídající koncový tag, nebo musí být počáteční tag zapsán jako element s prázdným obsahem. Chybou rovněž je, když se elementy v dokumentu kříží.
<b>Ukázka <i>překřížení</b> elementů</i>
Elementy jsou základním stavebním kamenem každého dokumentu. U každého počátečního tagu můžeme použít ještě atributy. Atributy se obvykle používají k upřesnění významu elementu.
<para zabezpečení="důvěrné">Nějaká tajná informace.</para>
V naší ukázce jsme atributu zabezpečení přiřadili hodnotu
důvěrné. Hodnotu atributu musíme vždy uzavřít do
uvozovek nebo do apostrofů. U jednoho tagu lze použít více
atributů najednou, stačí je oddělit mezerou.
<para zabezpečení="důvěrné" autor="Jan Novák">Nějaká tajná informace.</para>
Vzhledem k tomu, že se znaky `<' a
`>' používají pro oddělení tagů od okolního
textu, není možné tyto znaky zapsat do dokumentu jen tak. Pro jejich
zápis musíme použít tzv. znakové entity. Pro
zápis znaku `<' je určena entita
< a pro `>' to je
>.
Vyřešte nerovnost 3x < 5
Pro samotný zápis ampersandu (&) se
používá znaková entita &.
Křupavé rohlíčky vám dodá pekařství Žemlička & syn
Pokud potřebujeme uvnitř hodnoty atributu použít zároveň
uvozovky i apostrofy, s výhodou využijeme odpovídající
entity " a
'.
Každý XML dokument musí být celý obsažen v jednom elementu. Následující ukázka tedy nepředstavuje správný XML dokument.
<nadpis>Pokusný nadpis</nadpis> <odstavec>První odstavec</odstavec> <odstavec>Druhý odstavec</odstavec> <odstavec>Třetí odstavec</odstavec>
Stačí však přidat jeden element, který vše „obalí”, a vše je v pořádku.
<článek> <nadpis>Pokusný nadpis</nadpis> <odstavec>První odstavec</odstavec> <odstavec>Druhý odstavec</odstavec> <odstavec>Třetí odstavec</odstavec> </článek>
Splňuje-li dokument všechna výše uvedená pravidla, je syntakticky v pořádku a říkáme o něm, že je správně strukturovaný (well-formed). Takový dokument můžeme směle vypustit do světa, protože si s ním poradí všechny aplikace podporující formát XML.
Většinou však na dokument klademe různá omezení – chceme mít pod kontrolou elementy, které se mohou v dokumentu používat apod. V tomto případě musíme mít pro dokument k dispozici definici typu dokumentu (DTD). Pomocí parseru lze zkontrolovat, zda dokument danému DTD vyhovuje a je tzv. validní.
Současné počítače pracují vnitřně pouze s čísly. Na obrazovce sice vidíme texty, obrázky nebo třírozměrný model bludiště, ale někde za tím vším jsou již jen čísla. S texty se pracuje také jako s čísly. Každému znaku je přiřazeno číslo. Sada znaků a jím odpovídajících čísel je znaková sada.
Mezi nejstarší a nejznámější znakové sady patří ASCII. Tato znaková sada byla 7bitová – obsahovala znaky s kódy 0 až 127. Kromě písmen anglické abecedy, číslic a dalších znaků obsahovalo ASCII i některé řídící znaky. Potřebám angličtiny ASCII zcela vyhovovalo. Pro ostatní jazyky zde však chyběla některá písmena – pro češtinu například znaky s diakritikou. Vzniklo proto několik 8bitových znakových sad, které obsahovaly 256 znaků. Prvních 128 znaků bylo kvůli zpětné kompatibilitě shodných s ASCII. Horní část znakové sady pak obsahovala národní znaky.
Pro češtinu a další středoevropské jazyky existuje znaková sada ISO 8859-2, pro rušinu ISO 8859-5 apod. Microsoft ve Windows používá vlastní znakové sady, které se od ISO mírně liší. Pro češtinu je vhodná znaková sada windows-1250.
Pokud bychom však chtěli v jednom dokumentu používat více různých jazyků, dostaneme se do problémů, protože například znaková sada pro češtinu už neobsahuje azbuku. Postupně proto vznikly ještě další znakové sady, které obsahovaly více znaků. Mezi nejznámější patří 32bitové sady Unicode 3.0 a ISO 10646.
Výhodou těchto znakových sad je, že obsahují znaky všech běžně používaných jazyků – kromě češtiny či ruštiny zde nalezneme i pro nás exotické jazyky jako arabštinu, korejštinu, japonštinu a mnoho dalších.
XML používá jako znakovou sadu ISO 10646, protože je to dnes nejkomplexnější znaková sada a dá se očekávat, že v blízké budoucnosti ji bude přímo podporovat většina operačních systémů. ISO 10646 je vyvíjeno společně s Unicodem, takže definované znaky a jejich kódy se shodují. V následujícím textu se podíváme na to, co pro nás použití znakové sady ISO 10646 znamená v praxi.
Zatímco znaková sada definuje, jaké znaky a pod jakým číslem máme k dispozici, kódování znakové sady určuje, jak jsou jednotlivé kódy znaků převedeny na sekvenci bajtů, které znak reprezentují v paměti počítače, v souboru, při přenosu počítačovou sítí apod.
32bitová znaková sada na první pohled potřebuje pro uložení jednoho znaku 4 bajty. Pokud bychom takto přenášeli například jen anglické texty, bylo by to velice neefektivní. Z tohoto důvodu vzniklo kódování UTF-8 (UCS Transformation Format), které znaky z ASCII kóduje do jednoho bajtu; méně obvyklé znaky jsou pak kódovány v několika bajtech.
Kódování UTF-8 je identické s ASCII. Další znaky nad rámec ASCII jsou kódovány do sekvencí 2 až 6 bajtů. České znaky s diakritikou se v UTF-8 kódují do dvou bajtů.
Existuje ještě kódování UTF-16, které jeden znak ukládá do dvou bajtů. Využívá se přitom faktu, že v současné době je definováno jen něco málo přes 49 tisíc znaků. UTF-16 rovněž obsahuje mechanismus, jak ukládat až 1 milión znaků pomocí „surrogate pairs“ – jeden znak je uložen do čtyř bajtů.
Všechny aplikace, které podporují XML, by měly zvládat práci s kódováními UTF-8 a UTF-16. Pro nás tato kódování nejsou nejvhodnější, jsme zvyklí spíše na windows-1250 a ISO 8859-2. I když jsme dosud o windows-1250 a ISO 8859-2 mluvili jako o znakových sadách, můžeme na ně pohlížet i jako na kódování, která pokrývají pouze část ISO 10646.
U každého XML dokumentu můžeme určit používané kódování. Pokud však budeme používat jiné než UTF-8 nebo UTF-16, musíme si dát pozor, aby toto kódování podporovaly všechny aplikace, s nimiž budeme XML dokument zpracovávat.
Pokud v dokumentu používáme jiné kódování než UTF-8 nebo UTF-16, musíme ho specifikovat pomocí XML deklarace, která musí představovat první řádku dokumentu. Nejjednodušší XML deklarace má následující tvar.
<?xml version="1.0"?>
Deklaraci můžeme používat ve všech dokumentech. Standardně obsahuje pouze určení verze XML, pro zachování zpětné kompatibility v případě dalších verzích XML.
Použité kódování můžeme určit pomocí parametru
encoding, který je součástí XML deklarace.
<?xml version="1.0" encoding="windows-1250"?> <dokument> Dokument si vesele píši ve starém špatném Notepadu. </dokument>
Varování
Pokud dokument nepíšeme v UTF-8 nebo UTF-16, musíme kódování určit v XML deklaraci. Pokud to neuděláme, totálně tím zmateme většinu aplikaci, které s XML dokumentem mají pracovat.
Jeden XML dokument může být fyzicky uložen v několika souborech. Dílčí soubory se načítají jako tzv. externí entity. Pro každou externí entitu můžeme rovněž určit její kódování a to tak, že na prvním řádku použijeme deklaraci kódování. K této problematice se ještě podrobněji vrátíme, až si řekneme, jak rozdělit docbookový dokument do více souborů.
<?xml version="1.0" encoding="kódování"?>Může se stát, že náš editor nepodporuje všechny znaky, které
potřebujeme použít. Například píšeme dokument v češtině, ale
potřebujeme v něm použít řecké písmeno π. To se ve většině
8bitových kódování (jako např. windows-1250 nebo ISO 8859-2)
nevyskytuje. Proto můžeme do XML dokumentu vložit libovolný znak
pomocí znakové entity. Znaková entita má tvar
&#x, kde
kód znaku;kód znaku je kód znaku ze znakové sady
ISO 10646 zapsaný v šestnáctkové soustavě. Můžeme použít
i tvar &#, kde je kód
znaku;kód
znaku zapsán v desítkové soustavě.
Obsah kruhu se vypočte podle vzorce πr<sup>2</sup>. Originální způsob, jak vložit do textu mezeru.
Přehled znaků a jejich kódů nalezneme například na serveru sdružení Unicode nebo v mapě znaků ve Windows.
Pokud potřebujeme v dokumentu něco vysvětlit nebo část
textu dočasně skrýt, s výhodou k tomu použijeme komentář.
Komentář je součástí dokumentu, ale parsery jej ignorují a není
dále zpracováván. Komentář se zapisuje mezi znaky <!-- a -->.
<!-- Vysvětlující text -->
Komentář může obsahovat cokoliv, kromě posloupnosti znaků
--. V komentáři dokonce můžeme
používat tagy atd. Jsou však zcela ignorovány. To se hodí pro dočasné
vyřazení části dokumentu ze zpracování.
<para>První odstavec.</para> <!-- <para>Šéf mi leze krkem.</para> --> <para>Třetí odstavec.</para>
Pokud potřebujeme do dokumentu vložit větší kus textu, kde se
hojně používají znaky se speciálním významem jako
`<', `>' a
`&', je nepohodlné je zapisovat pomocí
znakových entit. Sekce CDATA oceníme zejména v případech, kdy je
součástí XML dokumentu kód nějakého programu nebo HTML či XML kód.
Použití sekcí CDATA si ukážeme na následujícím dokumentu.
<script language="JavaScript">
<![CDATA[
for (i=0; i < 10; i++)
{
document.writeln("<p>Ahoj</p>");
}
]]>
</script>Bez použití sekce CDATA by byl zápis přece jen poněkud krkolomný.
<script language="JavaScript">
for (i=0; i < 10; i++)
{
document.writeln("<p>Ahoj</p>");
}
</script>Obecně se tedy sekce CDATA zapisují jako
<![CDATA[.
Text přitom může obsahovat cokoliv, kromě sekvence znaků text]]>]]>. Konstrukce CDATA existuje v XML
pro větší pohodlí autorů, kteří zapisují XML kód ručně.
XML dokumenty mohou být zpracovávány různými programy. Někdy může být užitečné do dokumentu uložit řídící informace, které jsou určeny pouze pro některý program. Můžeme tak do dokumentu zařadit odkaz na styl definující zobrazení v prohlížeči, formátovacímu programu můžeme naznačit, kde má zalomit stránku. Moderní skriptové jazyky pro generování dynamických webových stránek se také zapisují přímo do těla dokumentů. Pro všechny tyto účely má XML k dispozici standardní způsob pro zařazení nestandardních informací. Na libovolné místo dokumentu (kromě značkování – podobně jako u komentářů) můžeme vložit instrukce pro zpracování (processing instructions). Tyto instrukce XML parser ignoruje, předá je nadřazené aplikaci – záleží na ní, zda je nějak využije. Syntaxe instrukcí je velice jednoduchá.
<?identifikátordata?>
Pomocí identifikátoru můžeme
rozlišovat jednotlivé druhy instrukcí – do jednoho dokumentu
můžeme umístit instrukce pro několik různých programů. Samotná
data instrukce mohou mít libovolný tvar,
ale nesmějí obsahovat sekvenci znaků ?>.
Například DSSSL a XSL styly rozpoznávají instrukci dbhtml, kterou lze ovlivňovat jméno souboru
v případě generování výstupu do HTML.
V DocBooku můžeme vytvářet mnoho druhů dokumentů, ale nejobvyklejší jsou knihy. Následující ukázka obsahuje velice jednoduchou knihu zapsanou v DocBooku.
Příklad 2.1. Kniha zapsaná v DocBooku – prvni.xml
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE book PUBLIC '-//OASIS//DTD DocBook XML V4.5//EN'
'http://www.oasis-open.org/docbook/xml/4.5/docbookx.dtd'>
<book lang="cs">
<bookinfo>
<title>První pokusná kniha</title>
<author>
<firstname>Jiří</firstname>
<surname>Kosek</surname>
</author>
</bookinfo>
<preface>
<title>Úvod</title>
<para>Odstavec textu.</para>
<para>...</para>
</preface>
<chapter>
<title>První kapitola</title>
<para>Text první kapitoly</para>
<para>...</para>
</chapter>
<chapter>
<title>Druhá kapitola</title>
<para>Text druhé kapitoly</para>
<para>...</para>
</chapter>
<appendix>
<title>První příloha</title>
<para>Text přílohy</para>
<para>...</para>
</appendix>
</book>
Dokument zapsaný v DocBooku sice přesně popisuje to co má – dokument, ale nijak nedefinuje, jak se má dokument zobrazit nebo zformátovat před tiskem. Pokud chceme XML dokument zobrazit musíme mít k dispozici styl, který definuje zobrazení jednotlivých elementů v dokumentu. Styly se zapisují v některém ze stylových jazyků. V současné době jsou nejpoužívanější následující stylové jazyky:
XSL – stylový jazyk navržený speciálně pro XML. Dnes se již hodně používá a do budoucnosti je nejperspektivnější. Existují volně dostupné XSL styly speciálně určené pro DocBook.
DSSSL – stylový jazyk původně navržený pro SGML, umí však zpracovat i XML dokumenty. Příliš se nerozšířil a vypadá to, že pozvolna ze světa zmizí. Existují volně dostupné DSSSL styly speciálně určené pro DocBook.
CSS (kaskádové styly) – pro formátování docbookových dokumentů většinou kvůli své jednoduchosti nepostačují.
FOSI – stylový jazyk používaný v některých komerčních aplikacích.
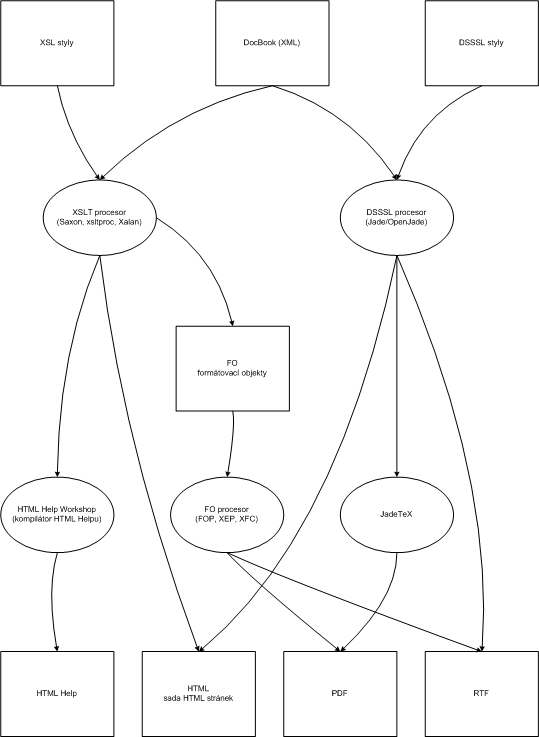
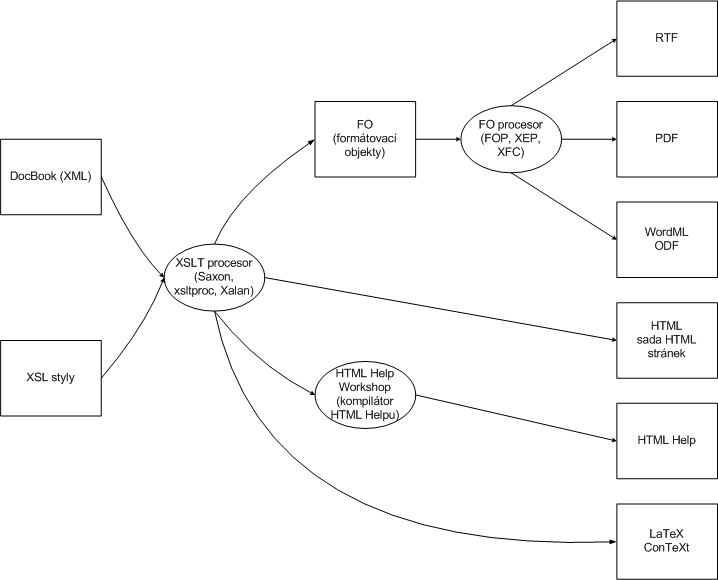
O instalaci stylů a nástrojů potřebných pro jejich zpracování se více dozvíte v kapitole 9 – „Instalace“. Tabulka 2.1 – „Výstupní formáty podporované DSSSL a XSL styly“ shrnuje nejpoužívanější výstupní formáty, které je možné pomocí jednotlivých stylů a nástrojů získat. Obdobnou informaci přináší i obrázek 2.1 – „Možnosti zpracování dokumentů XSL a DSSSL styly“.
Tabulka 2.1. Výstupní formáty podporované DSSSL a XSL styly
| Výstupní formát | Stylový jazyk | Potřebné nástroje |
|---|---|---|
| jedna HTML stránka | DSSSL | Jade |
| jedna HTML stránka | XSL | libovolný XSLT procesor |
| sada HTML stránek | DSSSL | Jade |
| sada HTML stránek | XSL | libovolný XSLT procesor |
| DSSSL | Jade+JadeTeX nebo Jade+Word+Distiller | |
| XSL | libovolný XSLT procesor + FO procesor (např. XEP) | |
| RTF | DSSSL | Jade |
| RTF | XSL | libovolný XSLT procesor + vhodný FO procesor (např. XFC) |
| WordML | XSL | libovolný XSLT procesor + vhodný FO procesor (např. XFC) |
| ODF | XSL | libovolný XSLT procesor + vhodný FO procesor (např. XFC) |
| PostScript | DSSSL | Jade+JadeTeX nebo Jade+Word+ovladač PS tiskárny |
| PostScript | XSL | libovolný XSLT procesor + FO procesor (např. XEP) |
| HTML Help | XSL | libovolný XSLT procesor + HTML Help WorkShop |
| Java Help | XSL | libovolný XSLT procesor + Java Help |
| Eclipse Help | XSL | libovolný XSLT procesor |
| manuálové stránky | XSL | libovolný XSLT procesor |
Pokud chceme použít DSSSL styly musíme mít k dispozici program Jade, který je umí aplikovat na SGML/XML dokumenty. Při spuštění je potřeba Jade zavolat s následujícími parametry:
jade-dstyl-tvýstupní_formátXML_deklaracesoubor.xml
Pokud například chceme získat RTF, zadáme příkaz:
jade -d c:\docbook\dsssl\print\docbook.dsl -t rtf c:\docbook\jade\xml.dcl prvni.xmlPo chvilce dostaneme soubor prvni.rtf, který můžeme načíst
v libovolném editoru, který podporuje formát RTF. Dokument je
automaticky editorem zformátován, obvykle jsou pouze chybná čísla
stran v obsahu. Při tisku se čísla stran správně přepočítají.
Ručně můžeme například v MS Wordu přepočítání vyvolat stiskem
kláves Ctrl+A a F9.
Pro získání HTML verze stačí místo stylů určených pro tisk
použít HTML styly a jako výstupní formát použít sgml:
jade -d c:\docbook\dsssl\html\docbook.dsl -t sgml c:\docbook\jade\xml.dcl prvni.xmlZískáme několik HTML stránek doplněných o přehledné navigační prvky a automaticky se rovněž vygeneruje obsah dokumentu. Pokud bychom chtěli získat celý dokument jako jednu stránku, při volání Jade předáme stylu parametr ovlivňující jeho chování:
jade -d c:\docbook\dsssl\html\docbook.dsl -V nochunks -t sgml c:\docbook\jade\xml.dcl prvni.xml > prvni.htmlV tomto případě Jade generovaný HTML kód zapisuje na
standardní výstup, a proto jsme ho pomocí > přesměrovali do souboru.
Jade ještě umí generovat výstup pro tisk ve formátech MIF (FrameMaker) a TeX – využívá se přitom balík maker JadeTeX. FrameMaker není v našich krajích moc rozšířen, proto se jím nebudeme zabývat. JadeTeX nepracuje za všech okolností správně a má problémy s delšími dokumenty.
Pro zpracování dokumentu pomocí XSL stylů musíme mít nějaký XSLT procesor a případně FO procesor. My použijeme Saxon a XEP.
Pro získání HTML verze dokumentu, můžeme použít příkaz:
saxon -o prvni.html prvni.xml c:\docbook\xsl\html\docbook.xslPokud chceme místo jedné HTML stránky, získat sadu stránek
provázaných odkazy, stačí použít styl chunk.xsl místo docbook.xsl:
saxon prvni.xml c:\docbook\xsl\html\chunk.xslPokud chceme získat nápovědu ve formátu HTML Help, spustíme
speciální styl htmlhelp.xsl. Ten
se chová velice podobně jako styl chunk.xsl a navíc vygeneruje soubor pro
kompilátor HTML Helpu. Při spouštění Saxonu ještě musíme nastavit
parametr, který určí kódování řídících souborů pro kompilátor HTML
Helpu.
saxon prvni.xml c:\docbook\xsl\htmlhelp\htmlhelp.xsl "htmlhelp.encoding=windows-1250"Automaticky se vygenerují soubory toc.hhc a htmlhelp.hhp. Druhý z nich je
projektovým souborem pro kompilátor HTML Helpu a můžeme ho proto
otevřít v programu HTML Help Workshop. Z menu vybereme
příkaz → . Do souboru htmlhelp.chm vygeneruje se nápověda ve
formátu HTML Help. Místo HTML Help Workshopu lze použít i řádkový
kompilátor hhc.
Poslední formát, který můžeme pomocí XSL stylů snadno získat je PDF. Nejprve si vytvoříme soubor obsahující formátovací objekty:
saxon -o prvni.fo prvni.xml c:\docbook\xsl\fo\docbook.xslz něj pak vygenerujeme PDF například pomocí XEPu:
xep -fo prvni.fo -pdf prvni.pdfXEP si také umí domyslet jméno PDF dokumentu sám, takže stačí zadat:
xep -fo prvni.foProces transformace na formátovací objekty a formátování můžeme spojit do jednoho kroku, protože XEP má v sobě zabudovaný Saxon:
xep -xml prvni.xml -xsl c:\docbook\xsl\fo\docbook.xslSprávnou syntaxi můžeme zkontrolovat pomocí libovolného validujícího parseru. Většina editorů má parser zabudován přímo v sobě. Mezi nejznámější řádkové parsery patří nsgmls pocházející ještě z dob SGML:
nsgmls-wxml-sc:\docbook\jade\xml.dcl prvni.xml
Další možností je např. xmllint:
xmllint--noout--validprvni.xml
Integrovanou funkci validace obsahuje i většina editorů XML.